
Jun 11 2026 · Piotr Płoński
Build a Web App for your Machine Learning model
Learn how to train a Machine Learning model with MLJAR AutoML, automatically generate a Web App, and publish it online for single and batch predictions.
Our latest articles about data science, machine learning, data analysis and programming. Enjoy!
Learn how to train a Machine Learning model with MLJAR AutoML, automatically generate a Web App, and publish it online for single and batch predictions.

Learn 10 practical ways to make predictions with a trained machine learning model, including batch CSV scoring, database predictions, scheduled jobs, REST APIs, streaming, edge deployment, web apps, spreadsheets, and Slack bots.

You will learn why ipynb notebook format is perfect for saving conversations with AI data analyst.

Discover the best AI courses for data analysis in 2026. Learn how to use ChatGPT, Gemini, Copilot, Python, SQL, Excel, and spreadsheets for faster data analysis.

Comprehensive overview of open-source AutoML tools in 2026, including active projects, maintenance status, tabular AutoML, foundation models, and agent-based AutoML systems.

I asked AI to load a CSV file for a medical data analysis use case. The code looked correct, but the dataframe was wrong. This is why checking AI output is so important.

AI generated a perfect data analysis report—but without visible code and workflow, it’s hard to trust the results. Here’s why transparency matters.
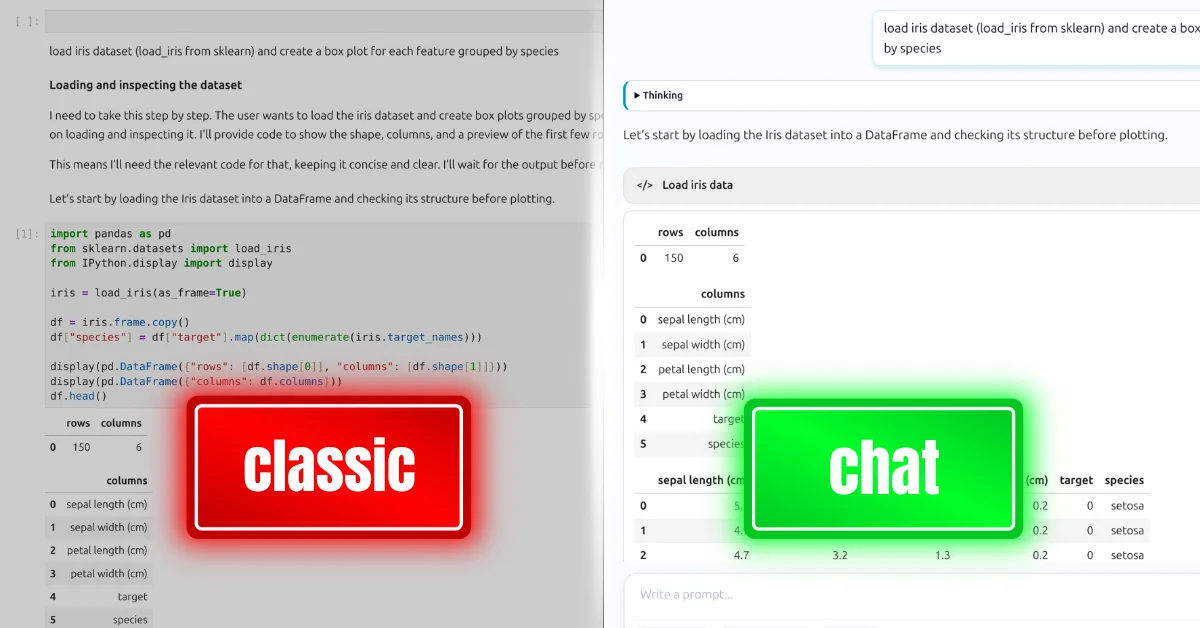
We describe how conversational notebook works in MLJAR Studio. It is a virtual AI Data Analyst that can answer data analysis questions using Python behind scenes. It was created on top of Jupyter notebook but has user frinedly design and is AI powered.

Use AI in healthcare without breaking HIPAA. Learn a safe workflow with MLJAR Studio, data anonymization, and practical examples to protect patient data and stay compliant.
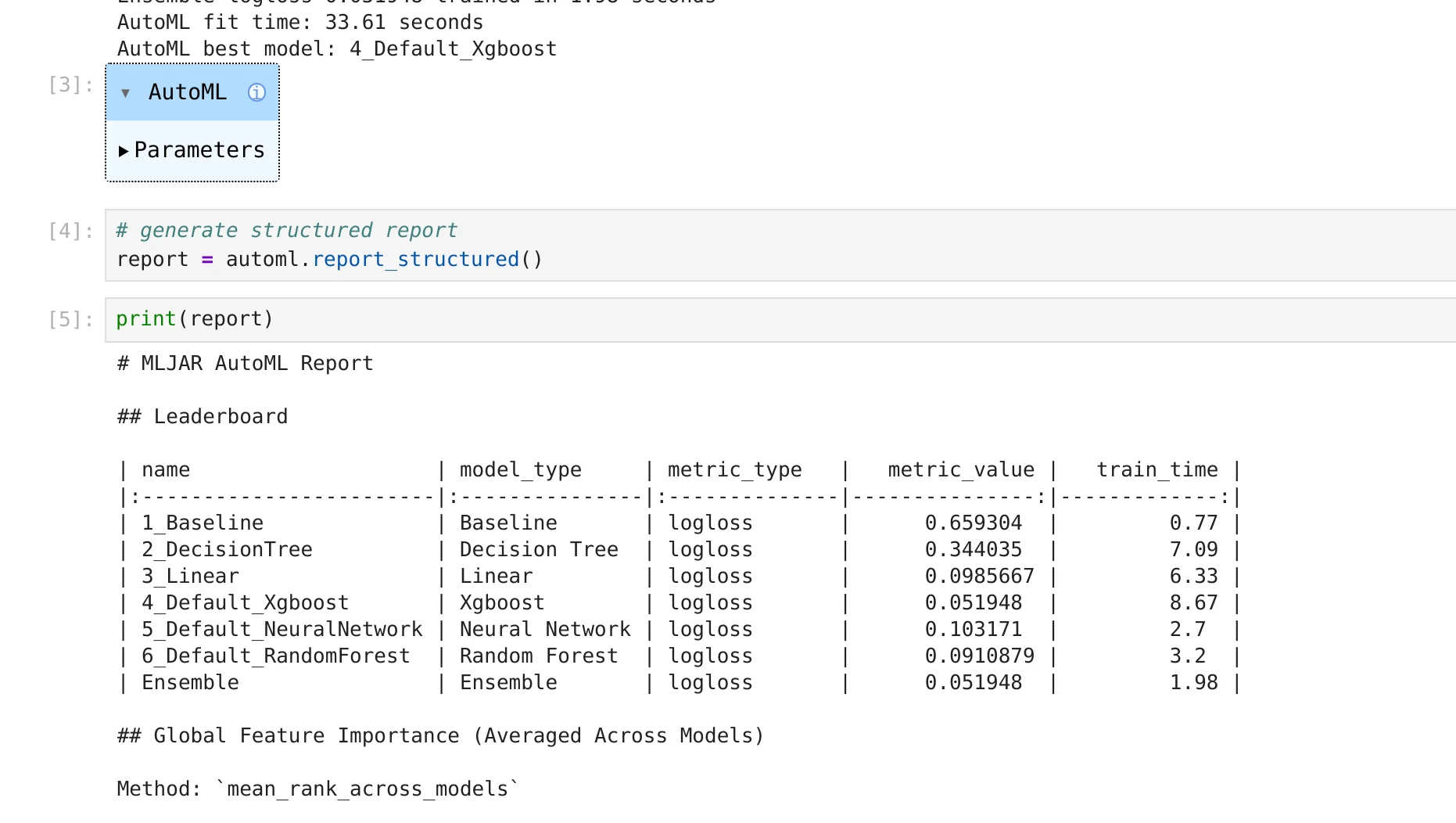
Generate structured AutoML reports in Python that are easy to parse, LLM-friendly, and perfect for notebooks and automated analysis.