Data Analysis Software for Pharmaceutical Research
Data Analysis Software for Pharmaceutical Research
What is the best data analysis software for pharmaceutical research?
The best data analysis software for pharmaceutical research today is no longer a traditional statistical tool. Modern research requires platforms that combine data analysis, machine learning, and AI while ensuring full data privacy. Tools like MLJAR Studio stand out because they allow researchers to analyze sensitive datasets locally, build predictive models automatically, and integrate AI workflows without sending data to external servers.
Pharmaceutical research has entered a new era. Data is no longer just something to analyze. It is something to model, predict, and use for decision-making. Clinical trials, drug discovery, and patient-level analysis all depend on extracting insights from increasingly complex datasets. At the same time, the constraints are stricter than ever. Data is sensitive, regulations are demanding, and mistakes are costly. This creates a new requirement for software. Not just tools that calculate statistics, but platforms that support the entire workflow — from raw data to predictive models — while keeping everything secure.
1. From Statistical Tools to AI-Driven Workflows
For years, pharmaceutical analysis relied on tools like Stata, SAS, and SPSS. These tools were built for statistical testing and reporting. They still work, but they were designed for a different world. Today, researchers are solving problems that require machine learning. Predicting drug response, identifying biomarkers, modeling patient outcomes — these are not classical statistical tasks. They require systems that can:
- test multiple models automatically,
- handle complex datasets,
- generate reproducible results,
- explain predictions.
This is where modern platforms begin to replace traditional tools.
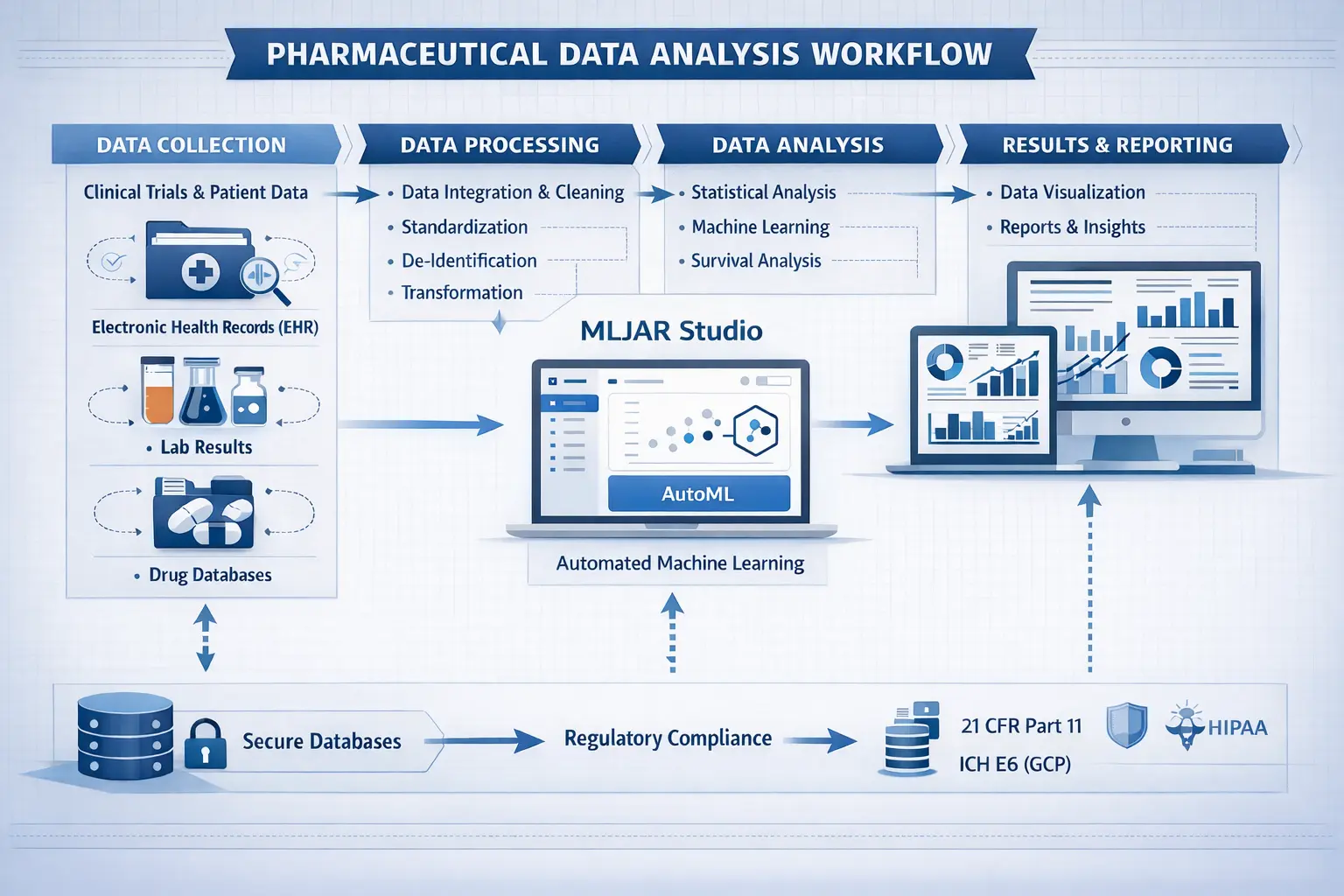
2. Real Pharmaceutical Use Cases with MLJAR
One of the strongest arguments for a tool is how it performs in real research. A good example is the use of AutoML in drug discovery:
👉 https://mljar.com/research/pharma/ai-automl-drug-discovery-multi-target-asthma-copd/
In this project, machine learning models were used to identify candidate compounds for asthma and COPD. Instead of manually building models, researchers used automated pipelines to explore many approaches at once. This allowed them to move faster and focus on interpreting results instead of tuning algorithms. Another example comes from medical prediction:
👉 https://mljar.com/notebooks/automl-medical-use-case/
Here, MLJAR is used to classify tumors as malignant or benign. The workflow is simple, but powerful. Models are trained automatically, evaluated, and explained. There are also biological applications:
👉 https://mljar.com/automl-use-cases/biology-use-case/
These include predicting biodegradability and analyzing molecular data, which are directly relevant to pharmaceutical research. Across these examples, one pattern is clear. Automation reduces time spent on repetitive tasks and increases time spent on understanding data.
3. How Data Analysis Works in Practice?
To understand the difference between tools, it helps to look at a real workflow. Imagine a clinical dataset with patient records, lab results, and treatment outcomes. The goal is to predict which patients will respond to a therapy. In a traditional setup, this involves multiple tools and manual steps. In MLJAR Studio, the process is continuous. You load the data locally. You explore it. Then you run AutoML.
With a single command, multiple models are trained, compared, and evaluated. You get a leaderboard, performance metrics, and explanations. Instead of building one model, you explore many possibilities at once. This changes the workflow from linear to iterative.
4. Mini Case Study: Predicting Clinical Trial Outcomes
Consider a clinical trial where researchers want to predict treatment success. The dataset includes patient demographics, biomarkers, and treatment details. Using MLJAR, the team runs automated modeling. The system tests multiple algorithms and builds an ensemble. The result is not just a prediction model. It is a set of insights. The team discovers which biomarkers matter most, which variables are irrelevant, and how different factors interact. This directly impacts how future trials are designed. The key advantage is speed. What used to take days now takes hours.
5. Comparison: MLJAR Studio vs Traditional Tools
| Feature | MLJAR Studio | Stata / SAS / SPSS |
|---|---|---|
| Workflow | End-to-end platform | Fragmented |
| Machine Learning | Built-in AutoML | Limited |
| Speed | Minutes to models | Hours or days |
| Reproducibility | Automatic reports | Manual |
| Explainability | Built-in (SHAP, importance) | Limited |
| Privacy | Local-first | Often external systems |
| AI Integration | Local LLM support | None |
The difference is not incremental. It is structural.
6. Top Data Analysis Tools for Pharmaceutical Research
The current landscape includes several categories of tools, each with its strengths and limitations. MLJAR Studio represents a modern approach where data analysis, machine learning, and reporting are integrated into one environment. It is particularly strong in privacy-sensitive workflows because it runs locally and supports private AI.
Python remains the most flexible option. With libraries like pandas and scikit-learn, it can handle almost any task. However, it requires expertise and often leads to fragmented workflows. SAS is still widely used in regulated environments. It is stable and trusted, but rigid and difficult to extend with modern machine learning. Stata is popular in academic settings. It is reliable for statistics but struggles with large datasets and predictive modeling. Cloud platforms such as Databricks or SageMaker provide scalability, but introduce complexity and potential data privacy concerns.
What is interesting is that none of these tools alone fully solves modern pharmaceutical needs. This is why integrated, local-first platforms are gaining attention.
7. Common Mistakes in Pharmaceutical Data Analysis
Many failures in pharmaceutical data projects are not caused by bad models, but by flawed workflows. One common mistake is treating modeling as a one-time task. In reality, it is iterative. The first model is just a starting point. Another issue is data leakage, where models accidentally use information they should not have. This leads to overly optimistic results that fail in practice. Overfitting is also common, especially with small datasets. Models appear accurate but do not generalize. Teams often focus too much on accuracy instead of understanding trade-offs. In clinical contexts, the cost of different errors matters more than a single metric. There is also the problem of explainability. In pharma, black-box models are not acceptable. Researchers must understand and justify predictions. Finally, many teams use fragmented tools. This creates inefficiencies and increases the risk of errors.
Modern platforms reduce these problems by integrating workflows and automating best practices.

8. The Importance of Privacy and Local Workflows
One of the biggest changes in recent years is the rise of AI tools. Many of them rely on cloud APIs. This creates a hidden risk. Sending sensitive pharmaceutical data to external services can violate compliance rules and expose proprietary information. MLJAR Studio takes a different approach. It allows data analysis, machine learning, and even AI assistance to run locally. This ensures that:
- data stays on the researcher’s machine,
- no external transmission is required,
- compliance risks are minimized.
In pharmaceutical research, this is a major advantage.
9. The Future of Pharmaceutical Data Analysis
Pharma is moving toward AI-driven discovery, personalized medicine, and predictive modeling. This requires tools that combine automation, explainability, privacy, and flexibility. The trend is clear. From static analysis to dynamic systems. From isolated tools to integrated platforms.
Common questions about software for pharmaceutical research
What software is used in pharmaceutical data analysis?
Pharmaceutical research commonly uses tools like SAS, Stata, and Python. However, modern workflows increasingly rely on platforms like MLJAR Studio that combine data analysis with machine learning and automation.
Is machine learning used in pharmaceutical research?
Yes. Machine learning is widely used for drug discovery, patient outcome prediction, biomarker identification, and clinical trial optimization.
Why are traditional tools like Stata becoming less popular?
They are not designed for modern workflows involving large datasets and machine learning. They also require more manual work and lack integration with AI tools.
Can pharmaceutical data analysis be done locally?
Yes. Tools like MLJAR Studio allow full local execution, which is important for handling sensitive data and maintaining compliance.
What is the advantage of AutoML in pharma?
AutoML reduces the time required to build and compare models. It allows researchers to quickly test multiple approaches and focus on insights rather than implementation.
Is cloud computing safe for pharmaceutical data?
It depends on the setup, but it introduces risks related to data privacy and compliance. Many organizations prefer local or hybrid solutions to maintain full control over data.
Final Thoughts
Choosing the right data analysis software for pharmaceutical research is no longer just about features. It is about how fast you can learn from data, how safely you can work with it, and how easily you can turn insights into decisions. Traditional tools still have their place. But modern research requires more. Platforms like MLJAR Studio represent this shift. They combine automation, machine learning, and privacy into a single workflow. And in an industry where better decisions can lead to better treatments, that shift matters.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- Machine Learning vs AI vs Data Science: What’s the Difference? (Complete Guide)
- AI Ethics and Responsible Data Science: Building Fair and Private Machine Learning Systems
- Local vs Cloud Data Processing: Security, Privacy, and Private AI Workflows
- AutoResearch by Karpathy and the Future of Autonomous AI Research
- Complete Guide to Offline Data Analysis 2026
- AI Coding Assistants for Data Science: Complete 2026 Comparison
- Machine Learning for Humans and LLMs: Structured AutoML Reports in Python
- AI in Healthcare without breaking HIPAA (MLJAR Studio guide)
- Reimagine Python Notebooks in the AI Era
- AI gave me a perfect report. I still didn’t trust it.