What is Random Forest?
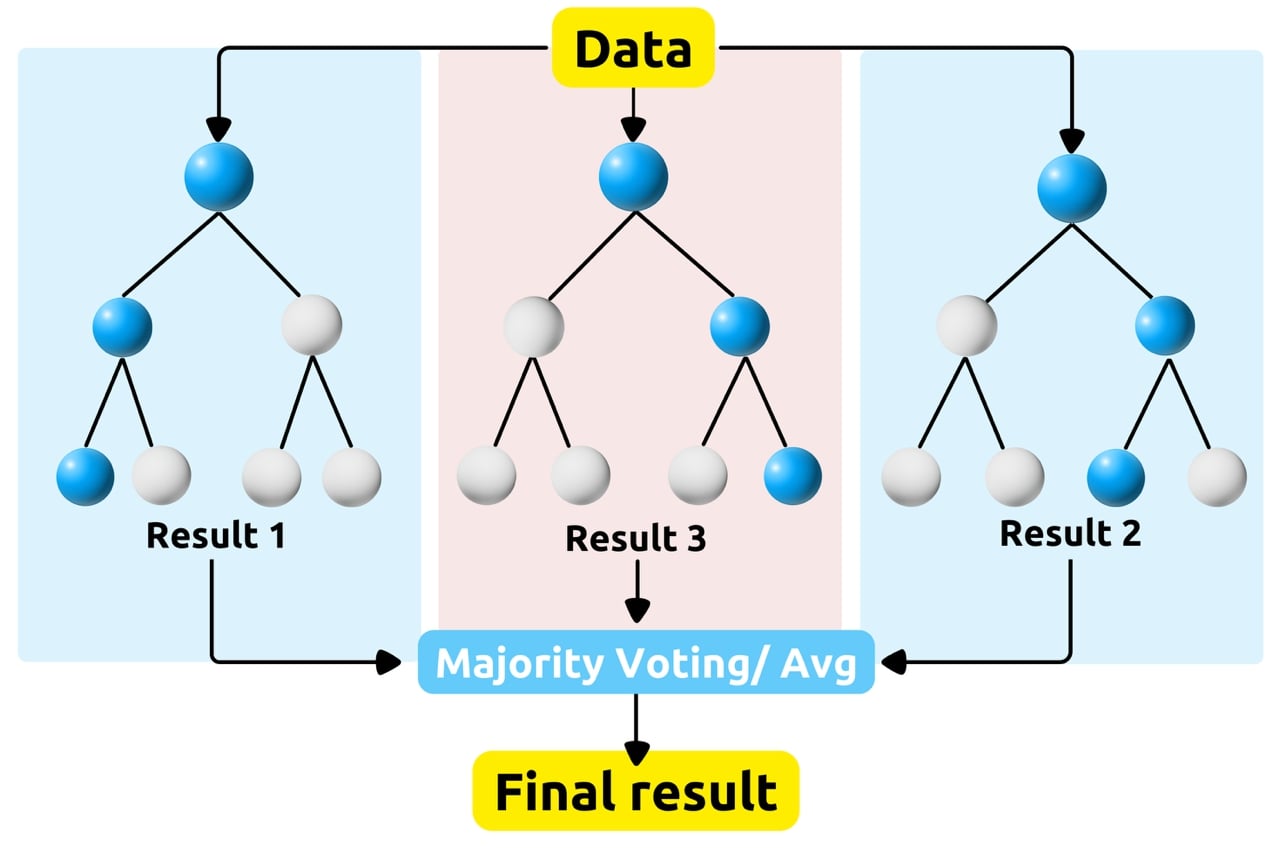
Random Forest is a popular Machine Learning algorithm that belongs to the ensemble learning category. It's used for both classification and regression tasks. Here's a breakdown of how it works:
-
Decision Trees are models used in this algorithm. These a tree-like structure where each internal node represents a "test" on an attribute (e.g., whether a feature is above or below a certain value), each branch represents the outcome of the test, and each leaf node represents a class label (in classification) or a numerical value (in regression). You can find out more about it in our Decision Tree glossary entry.
-
Ensemble Learning is a method, that combines multiple individual models to create a more powerful model. In the case of Random Forest, these individual models are decision trees. Ensemble uses two types of techniques:
- Bagging or Bootstrap Aggregation (parallel data flow)
- Boosting (sequential models composition)
Randomness in Random Forest:
The "Random" in Random Forest comes from:
-
Random Sampling - Random Forest randomly selects a subset of the training data (with replacement), known as bootstrapping. This creates multiple different datasets for training each decision tree.
-
Random Subset of Features - used at each node in the decision tree. Random Forest only considers a random subset of features to make the split. This helps to decorrelate the trees and improve the overall performance of the model.
Voting or Averaging:
Once all the decision trees are trained, in the case of classification, each tree "votes" for a class, and the class with the most votes becomes the model's prediction. In the case of regression, the outputs of all the trees are averaged to make the final prediction.
Forests' history:
The term "Random Forest" and the algorithm as we know it today were popularized and formalized by Leo Breiman and Adele Cutler.
Leo Breiman, a prominent statistician and professor at the University of California, Berkeley, introduced the concept of Random Forest in a paper titled "Random Forests" published in 2001. He further expanded on the idea in subsequent works.
Adele Cutler, along with Leo Breiman, co-authored the original paper and contributed to the development and refinement of the Random Forest algorithm.
Train Random Forest in Python:
Those who want to try using it themself can use Python library scikit-learn, often abbreviated as sklearn. It is a popular open-source machine learning library for Python. It provides simple and efficient tools for data mining and data analysis, built on top of libraries like NumPy, SciPy, and matplotlib. It even has premade dataset for you to train and evaluate Random Forest classifier.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X = iris.data # Features
y = iris.target # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize Random Forest classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the classifier
rf_classifier.fit(X_train, y_train)
# Make predictions on the test set
predictions = rf_classifier.predict(X_test)
# Evaluate model performance
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)
You can adjust the parameters of the classifier and explore different evaluation metrics to further analyze the model's performance.
Random Forest Use cases:
Random Forests find numerous applications in real-life projects across various domains due to their versatility, robustness, and effectiveness in handling complex datasets. For example in:
-
Marketing and E-commerce:
-
Customer Segmentation: Random Forests are used to segment customers into different groups based on demographic, behavioral, or transactional data. This segmentation helps in targeted marketing campaigns and personalized customer experiences.
-
Recommendation Systems: E-commerce platforms and content streaming services utilize Random Forests in recommendation systems to suggest products, movies, or content based on user preferences, browsing history, and purchase behavior.
-
-
Environmental Science:
-
Species Classification: Random Forests are used in environmental science for species classification and biodiversity assessment. They analyze environmental features and habitat data to classify species of plants and animals, aiding in conservation efforts.
-
Climate Modeling: Random Forests are employed in climate modeling to analyze climate data, predict weather patterns, and simulate the impact of climate change on ecosystems and human populations.
-
-
Manufacturing and Industry:
-
Predictive Maintenance: Manufacturing companies use Random Forests for predictive maintenance of machinery and equipment. They predict equipment failures and perform preventive maintenance based on sensor data, historical maintenance records, and operational parameters.
-
Quality Control: Random Forests are used in quality control processes to identify defects in products or detect anomalies in manufacturing processes. They analyze sensor data and production metrics to ensure product quality and process efficiency.
-

Pros and Cons:
Random Forests offer several advantages and disadvantages, which should be considered when choosing this algorithm for a particular task.
-
Advantages:
-
Overgitting resistance - Random Forest is less prone to overfitting compared to individual decision trees, but still Random Forest can overfit.
-
Large dataset stability - It can handle large datasets with high dimensionality.
-
Feature callback - It provides a feature importance measure, which can be helpful in feature selection.
-
-
Disadvantages:
-
Costly exploatation - Random Forest can be computationally expensive, especially for large numbers of trees and features.
-
Imbalance vulnerability - It may not perform well on very imbalanced datasets.
-
Lack of insight - It's considered a "black box" model, meaning it's not as interpretable as simpler models like linear regression.
-
Literature:
There are numerous articles, reports, and research papers on Random Forests available online, covering various aspects of the algorithm, its applications, and advancements. Here are some notable resources that provide comprehensive insights into Random Forests:
-
"Random Forests" by Leo Breiman - This seminal paper by Leo Breiman, published in 2001, introduces the concept of Random Forests and provides a detailed explanation of the algorithm, its properties, and applications.
-
"The Elements of Statistical Learning" by Trevor Hastie, Robert Tibshirani, and Jerome Friedman - Chapter 15 of this book covers Random Forests in depth, discussing topics such as ensemble learning, bagging, and tree-based methods.
-
"Random Forests for Big Data" by Robin Genuer, Jean-Michel Poggi, Christine Tuleau-Malot, Nathalie Vialaneix - This paper explores the scalability and performance of Random Forests for large datasets, discussing strategies for parallelization and optimization.
-
"Random Forests for Genomic Data Analysis" by Xi Chen and Hemant Ishwaran - This paper explores the use of Random Forests for analyzing genomic data, including gene expression analysis, classification of genetic variants, and biomarker discovery.
Conclusions:
Overall, Random Forest is a versatile and powerful algorithm that is widely used in various machine learning applications across different domains. Random Forests remain a popular choice for many machine learning tasks due to their accuracy, robustness, and ability to handle complex datasets. When applied appropriately and tuned carefully, Random Forests can yield excellent results in real-world projects.
MLJAR Glossary
Learn more about data science world
- What is Artificial Intelligence?
- What is AutoML?
- What is Binary Classification?
- What is Business Intelligence?
- What is CatBoost?
- What is Clustering?
- What is Data Engineer?
- What is Data Science?
- What is DataFrame?
- What is Decision Tree?
- What is Ensemble Learning?
- What is Gradient Boosting Machine (GBM)?
- What is Hyperparameter Tuning?
- What is IPYNB?
- What is Jupyter Notebook?
- What is LightGBM?
- What is Machine Learning Pipeline?
- What is Machine Learning?
- What is Parquet File?
- What is Python Package Manager?
- What is Python Package?
- What is Python Pandas?
- What is Python Virtual Environment?
- What is Random Forest?
- What is Regression?
- What is SVM?
- What is Time Series Analysis?
- What is XGBoost?