What is Parquet File?
Parquet is a columnar storage file format optimized for use with big data processing frameworks like Apache Hadoop and Apache Spark. It is designed to bring efficiency to data storage and retrieval, offering significant advantages in terms of performance and storage compared to traditional row-based file formats.
Origin of Parquet:
Parquet was created as a collaboration between Twitter (X nowadays) and Cloudera and released in 2013. The goal was to develop a file format that could efficiently store and process large datasets, addressing the limitations of row-oriented storage formats in big data ecosystems.
Utilization of Parquet:
Parquet is widely utilized in various big data and analytics applications, including:
- Big Data Processing Frameworks - Commonly used with Apache Hadoop, Apache Spark, Apache Drill, and Apache Impala.
- Data Warehousing - Often employed in data warehouse solutions like Amazon Redshift Spectrum, Google BigQuery, and Snowflake.
- Data Lakes - Used to store large-scale datasets in data lakes, such as those built on Amazon S3, Azure Data Lake Storage, and Google Cloud Storage.
- ETL Processes - Beneficial in extract, transform, load (ETL) pipelines due to its efficient data encoding and compression capabilities.
Parquet, but not a floor:
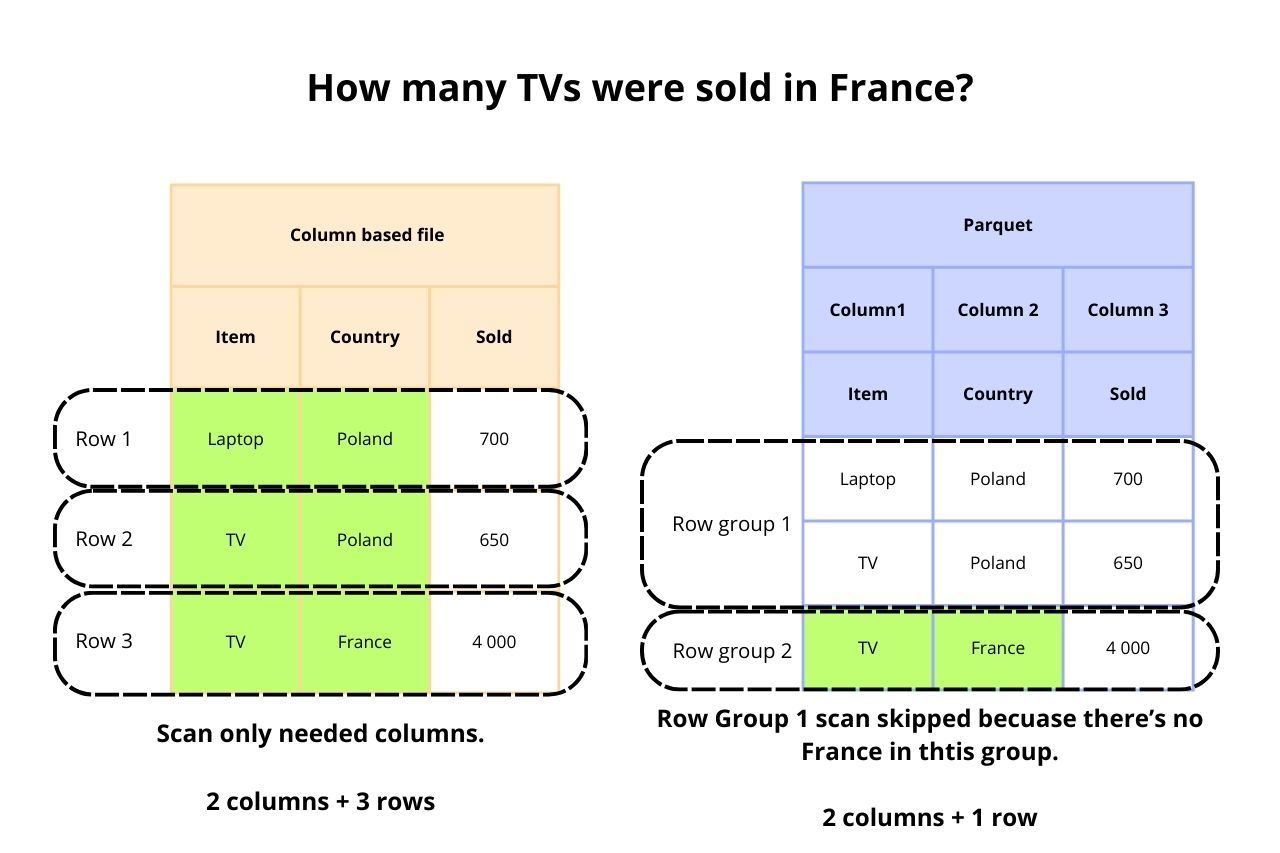
Why Parquet Uses Columns Instead of Rows?
Efficiency in Analytical Queries:
- Selective Column Reading - Analytical queries often require accessing only a few columns of a large dataset. Columnar storage formats like Parquet allow these queries to read only the necessary columns, reducing the amount of data read from disk and thus improving query performance.
Compression:
- Better Compression Ratios - Columns tend to have similar data types and values, which can be more effectively compressed than rows. This results in reduced storage space and faster read/write operations due to smaller data sizes.
Improved I/O Performance:
- Efficient Data Access Patterns - By storing data column-by-column, Parquet can exploit CPU cache and memory bandwidth more effectively. It allows for better utilization of I/O bandwidth by reading contiguous blocks of data that are relevant to a specific query.
What it changes in Data Access Patterns?
Read Performance:
- Improved Read Performance - Since only the required columns are read, the amount of I/O is significantly reduced, leading to faster query execution times. This is especially beneficial in environments where I/O is a bottleneck.
Write Performance:
- Initial Write Complexity - Writing data in a columnar format can be more complex compared to a row-based format, as data needs to be reorganized into columns. However, this overhead is often outweighed by the subsequent read performance gains.
Compression and Encoding:
- Advanced Compression - Columnar storage allows for the use of advanced compression algorithms that are more effective on homogeneous data. For instance, run-length encoding (RLE) or dictionary encoding can be applied to compress repeated values within a column efficiently.
Storage Efficiency:
- Reduced Storage Costs - With better compression and less redundant data storage, Parquet files typically require less disk space compared to row-based formats. This is crucial for large-scale data storage and management.
Practical Implications:
-
Big Data and Analytics:
- Faster Analytics - Parquet is particularly advantageous for big data and analytics workloads where read-heavy operations dominate. It allows for quick retrieval of relevant data, making it ideal for data warehousing and analytics platforms.
-
Resource Utilization:
- Optimized Resource Usage - By reducing the amount of data read and processed, Parquet helps in optimizing the use of computational and I/O resources, leading to cost savings in cloud-based environments where resource usage directly translates to costs.
-
Data Processing Frameworks:
- Integration with Big Data Tools - Parquet is designed to integrate seamlessly with big data processing frameworks like Apache Spark, Hive, and Impala, which are optimized for columnar data access patterns. This integration further enhances performance and scalability in data processing tasks.
Comparison with JSON and CSV
| Parquet | JSON | CSV | |
|---|---|---|---|
| Structure | Columnar format | Semi-structured format, often used for nested data | Row-based format, simple and widely used for tabular data |
| Performance | Highly efficient for read-heavy workloads and analytical queries, as it allows for selective reading of columns and supports advanced compression and encoding schemes | Generally slower for both read and write operations compared to Parquet, especially for large datasets | Faster to read and write for small to moderately sized datasets, but can be inefficient for very large datasets due to lack of compression and need to read the entire file for columnar operations |
| Storage Efficiency | Highly efficient, as it supports various compression algorithms and stores data in a compact, columnar format | Less efficient for storage due to its verbose text-based structure | More efficient than JSON for simple tabular data but less so compared to Parquet, especially for large datasets |
| Flexibility | Less flexible for data interchange, primarily optimized for analytical workloads | Highly flexible and widely used for data interchange due to its ability to represent complex and nested data structures | Very simple and widely supported, but limited to flat, tabular data without nested structures |
| Use Cases | Best suited for analytical workloads, big data processing, and data warehousing | Ideal for APIs, configuration files, and situations where data interchange and human readability are important | Useful for simple data interchange, spreadsheets, and scenarios requiring compatibility with a wide range of tools |
In summary, Parquet is a highly efficient columnar storage format tailored for big data and analytical use cases, offering significant advantages in performance and storage efficiency over JSON and CSV, which are better suited for different scenarios involving data interchange and simpler datasets.
Pros and Cons:
Advantages:
- Optimized for read-heavy, analytical workloads.
- Superior compression and storage efficiency.
- Enhanced performance for selective queries.
Disadvatages:
- More complex write operations.
- Initial learning curve for implementation and use.
Literature:
-
"Hadoop: The Definitive Guide: Storage and Analysis at Internet Scale" by Tom White - This book provides comprehensive coverage of Hadoop, including storage formats like Parquet.
-
"Learning Spark: Lightning-Fast Big Data Analysis" by Holden Karau, Andy Konwinski, Patrick Wendell, and Matei Zaharia - Covers the integration of Parquet with Apache Spark, illustrating how Parquet can be used for efficient data storage and retrieval in Spark applications.
Conclusions:
In conclusion, Parquet stands out as a highly efficient and scalable file format for big data environments, offering significant advantages in terms of performance, storage efficiency, and integration with modern data processing tools. Its adoption can lead to substantial improvements in the management and analysis of large datasets, making it a preferred choice for organizations dealing with big data and complex analytical workloads.
MLJAR Glossary
Learn more about data science world
- What is Artificial Intelligence?
- What is AutoML?
- What is Binary Classification?
- What is Business Intelligence?
- What is CatBoost?
- What is Clustering?
- What is Data Engineer?
- What is Data Science?
- What is DataFrame?
- What is Decision Tree?
- What is Ensemble Learning?
- What is Gradient Boosting Machine (GBM)?
- What is Hyperparameter Tuning?
- What is IPYNB?
- What is Jupyter Notebook?
- What is LightGBM?
- What is Machine Learning Pipeline?
- What is Machine Learning?
- What is Parquet File?
- What is Python Package Manager?
- What is Python Package?
- What is Python Pandas?
- What is Python Virtual Environment?
- What is Random Forest?
- What is Regression?
- What is SVM?
- What is Time Series Analysis?
- What is XGBoost?