Machine Learning Basics: Beginner’s Guide 2026
Quick answer: Machine learning basics include data, features, models, evaluation, and iteration. This guide gives a practical beginner path with modern tools.
Machine learning is one of the most exciting areas of modern technology. It powers recommendation systems, fraud detection, medical diagnostics, self-driving cars, and many AI tools we use every day. But for beginners, machine learning often looks complicated. There are many unfamiliar terms, algorithms, and tools. The good news is that learning machine learning today is easier than ever. Powerful open-source libraries, interactive notebooks, and AI assistants help beginners explore data and build models much faster than before. In this beginner’s guide you will learn:
- what machine learning is
- the main types of machine learning
- common algorithms used in practice
- the typical machine learning workflow
- tools that help you get started faster
By the end of this article you will understand the foundations of machine learning and how to start your first projects.
1. What Is Machine Learning?
Machine learning is a branch of artificial intelligence that focuses on building algorithms that learn patterns from data. Instead of writing explicit rules for every possible situation, we provide examples and let the algorithm learn the relationships. For example, imagine we want to build a system that detects spam emails. Instead of writing thousands of rules like:
if subject contains "free money" → spam
we can give the algorithm thousands of labeled emails. The algorithm then learns patterns that distinguish spam from normal messages. Once trained, it can classify new emails automatically. This idea is the core of machine learning. Machine learning is widely used in many industries:
- recommendation systems (Netflix, Amazon),
- fraud detection in banking,
- medical image analysis,
- search engine ranking,
- voice assistants,
- customer behavior prediction.
In simple terms, machine learning allows computers to learn from data and improve their performance over time.
2. Types of Machine Learning
Machine learning algorithms are usually divided into three main categories.
Supervised Learning
Supervised learning is the most common type of machine learning. In this approach, models are trained using labeled data. Each example contains both input data and the correct output. For example:
input --------- output
house size --> house price
email text --> spam or not spam
customer features --> will buy or not
Popular supervised learning algorithms include linear regression, logistic regression, decision trees, random forests, gradient boosting. Supervised learning is usually the best starting point for beginners.
Unsupervised Learning
Unsupervised learning is a type of unsupervised machine learning that works with unlabeled data, meaning that the correct outputs are not known in advance. Instead of predicting a predefined result, the algorithm tries to identify patterns, relationships, or hidden structures directly from the data. This approach is commonly used in tasks such as customer segmentation, anomaly detection, dimensionality reduction, and grouping similar data points through clustering. Several unsupervised learning algorithms are widely used for these tasks, including k-means clustering, hierarchical clustering, and DBSCAN. Each of these algorithms is designed to discover different types of structure within complex datasets.
Reinforcement Learning
Reinforcement learning is used when an agent learns through interaction with an environment. The system receives rewards or penalties depending on its actions and gradually learns strategies that maximize reward. Reinforcement learning is usually studied after gaining experience with supervised learning.
3. The Machine Learning Workflow
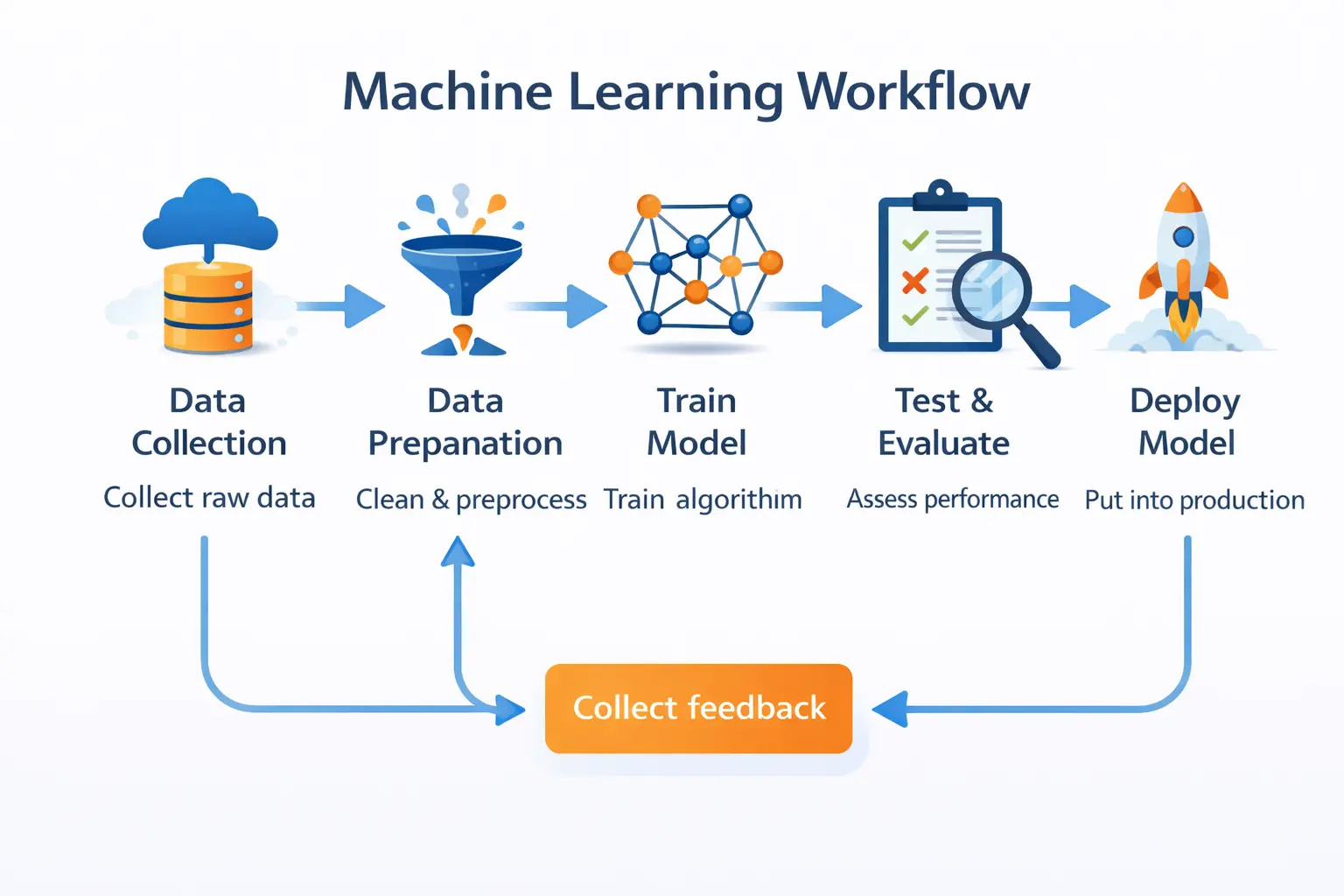 Most machine learning projects follow a similar workflow.
Most machine learning projects follow a similar workflow.
Data Collection
Machine learning begins with data. Data may come from many sources:
- databases,
- CSV files,
- APIs,
- sensors,
- web scraping. The quality and quantity of data strongly influence model performance.
Data Exploration
Before building models, data scientists explore and understand the dataset. Typical tasks include identifying missing values, visualizing distributions, detecting outliers, and understanding relationships between variables. Interactive environments help a lot at this stage. For example, MLJAR Studio provides a notebook environment where users can explore datasets interactively and even ask an AI assistant to generate Python code for analysis. This approach makes data exploration faster and easier for beginners.
Feature Engineering
What is feature engineering in machine learning? Feature engineering is the process of transforming raw data into meaningful variables that improve the performance of machine learning models. Features are the variables that machine learning models use to make predictions. In practice, raw data often cannot be used directly and needs to be transformed into a more useful representation. This step, known as feature engineering in machine learning, involves creating meaningful input variables that help models capture patterns in the data. For example, we might extract the year from a date, create ratios between numerical variables, convert categorical values into numerical form, or scale numerical features so they have comparable ranges. Good feature engineering helps models better understand the structure of the data and often leads to significantly better prediction performance.
Model Training
After preparing the data, we train machine learning models. Typically, data scientists test multiple algorithms and many parameter configurations. This process can be time-consuming. Automated machine learning tools such as MLJAR AutoML can help by automatically testing many models, tuning hyperparameters, and generating reports comparing model performance. AutoML tools allow beginners to experiment with machine learning models without spending hours configuring algorithms manually.
Model Evaluation
After training, machine learning models must be evaluated to determine how well they perform. This step, known as model evaluation in machine learning, helps measure how accurately a model makes predictions and whether it will work well on new data. Various machine learning evaluation metrics are used depending on the type of problem being solved. For classification tasks, common metrics include accuracy, precision, recall, and the F1 score, which measure how effectively the model identifies different classes. For regression problems, typical metrics include mean squared error, mean absolute error, and the R² score, which evaluate how close the predicted values are to the actual results. Proper evaluation is essential because it helps ensure that the model generalizes well to unseen data rather than simply memorizing patterns from the training dataset.
Deployment and Sharing Results
Model deployment in machine learning is the process of making a trained model available so it can generate predictions on new data. Once a machine learning model performs well, the next step is to share the results or deploy the model so it can be used in real applications. Model deployment can take many forms depending on the needs of the project. For example, predictions may be delivered through a web API, integrated into dashboards, executed as batch predictions on new datasets, or embedded into internal applications used by a company. In many projects, it is also important to present results in a simple and interactive way so that colleagues, analysts, or decision-makers can easily work with the model. Tools such as MLJAR Mercury help simplify this process by allowing users to convert Python notebooks into interactive web applications. Instead of sharing raw code, data scientists can create simple interfaces where users upload data, run predictions, and explore results directly in the browser.
4. Popular Machine Learning Algorithms for Beginners
Linear Regression
Linear regression in machine learning is an algorithm used to predict numeric values based on relationships between variables. A linear regression model learns how different factors influence a target variable and then uses this relationship to make predictions. For example, it can be used to predict house prices by analyzing features such as location, property size, and the number of rooms. By learning patterns from historical data, the model can estimate prices for new houses that were not included in the training dataset. Although linear regression is relatively simple compared to more advanced algorithms, it remains one of the most important techniques for understanding how machine learning models learn relationships from data.
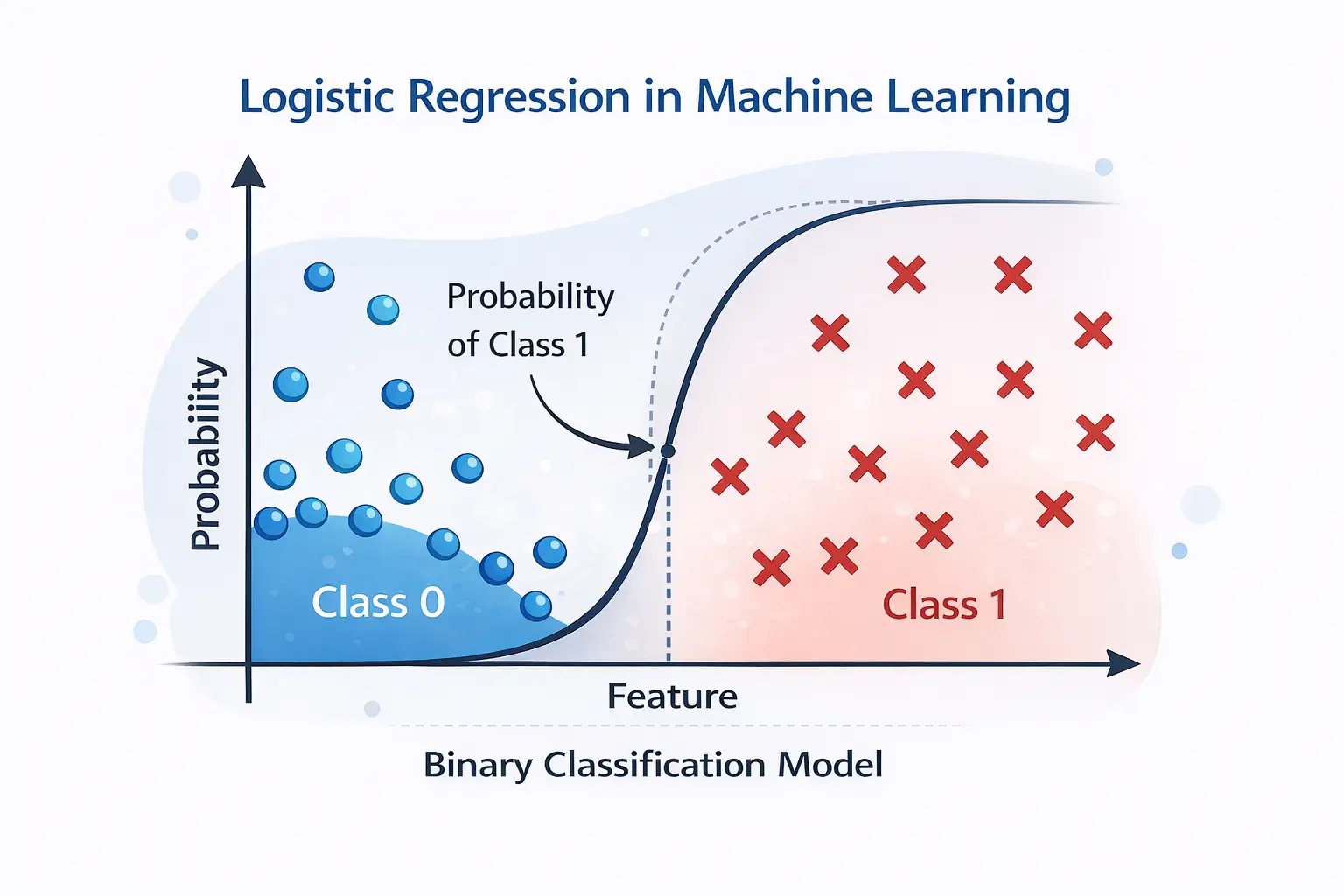
Logistic regression
Logistic regression in machine learning is a widely used algorithm for classification tasks, even though its name may suggest that it is related to regression. In reality, logistic regression is designed for logistic regression classification, where the goal is to determine which category a data point belongs to. It works by estimating the probability that an observation belongs to a particular class. For example, a binary classification model based on logistic regression can be used for spam detection, medical diagnosis, or customer churn prediction. The model produces probabilities between 0 and 1, which represent how likely it is that a given example belongs to a specific class.
Decision Trees
A decision tree in machine learning is a predictive model that makes decisions by splitting data into branches based on simple rules. Decision trees create models that resemble flowcharts, where each branch represents a decision based on the value of a particular feature. The model gradually splits the data into smaller groups until it reaches a final prediction. For example, a loan approval model might first check whether a person’s income exceeds a certain threshold and then apply additional conditions, such as evaluating their credit score. One of the main advantages of decision trees is that they are easy to interpret and understand. Unlike many complex machine learning models, decision trees can be visualized in a way that clearly shows how predictions are made. This transparency makes them particularly useful in situations where model explainability is important. To make visualization easier, tools such as SuperTree, an open-source package developed by MLJAR, allow data scientists to display decision trees in a clear and interactive way. SuperTree helps explore the structure of a tree, understand decision paths, and present models visually when explaining results to others.
Random Forest
Random forests are an ensemble machine learning method that combines many decision trees to improve prediction accuracy. Instead of relying on a single tree, a random forest builds multiple trees on different subsets of the data and then aggregates their predictions. This approach usually leads to stronger performance across many datasets, reduces the risk of overfitting, and makes the model more robust to noisy data. Because of these advantages, random forests are widely used in real-world machine learning systems and are considered one of the most reliable algorithms for many practical problems.
5. Tools That Make Machine Learning Easier
Modern tools significantly simplify the process of building machine learning models. One example is MLJAR Studio, a desktop environment designed specifically for data science. It combines several important tools into one platform:
- interactive notebooks
- AI coding assistant
- integrated AutoML
- local execution for privacy Instead of writing everything from scratch, users can explore datasets, generate visualizations, and train models directly inside the notebook. Another useful tool is MLJAR AutoML, an open-source automated machine learning framework. It automatically: tests multiple algorithms, tunes hyperparameters, evaluates models, generates experiment reports. Finally, MLJAR Mercury helps transform Python notebooks into interactive web applications, making it easy to present machine learning results. Together these tools provide a complete workflow:
data exploration → model training → sharing results
6. Tips for Learning Machine Learning Faster
Here are several tips for beginners.
Start with simple algorithms
Focus first on algorithms such as regression and decision trees. Avoid jumping directly into complex deep learning models.
Work on real datasets
Learning happens fastest when working with real data. Good sources include: Kaggle datasets, public research datasets, open government data.
Build small projects
One of the best ways to learn machine learning is by building small projects. Instead of focusing only on theory, it is much more effective to experiment with simple real-world problems. For example, you might try predicting house prices using basic features such as size and location, classifying flower species based on their measurements, analyzing sales data to identify trends, or building a simple model that detects spam messages. Working on these kinds of projects helps beginners understand how machine learning models behave in practice and gradually develop intuition about how different algorithms learn from data.
Use modern tools
Interactive notebooks, AutoML systems, and AI assistants can accelerate learning and allow beginners to focus on understanding machine learning concepts.

Common Questions About Machine Learning
What is machine learning in simple terms?
Machine learning is a method of teaching computers to recognize patterns in data. Instead of writing explicit rules, algorithms learn from examples and make predictions based on new data.
Is machine learning the same as artificial intelligence?
Machine learning is a subset of artificial intelligence. Artificial intelligence is a broader field focused on building intelligent systems. Machine learning is one of the main approaches used to achieve this.
Do I need mathematics to learn machine learning?
Basic mathematics such as statistics and probability helps, but beginners can start learning machine learning without deep mathematical knowledge. Understanding concepts and practicing with datasets is often more important at the beginning.
Which programming language is best for machine learning?
Python is currently the most popular language for machine learning. It has a large ecosystem of libraries such as: scikit-learn, pandas, LightGBM, XGBoost, TensorFlow, PyTorch, mljar-supervised.
What is AutoML?
AutoML stands for automated machine learning. AutoML tools automatically perform tasks such as model selection, hyperparameter tuning, and evaluation. Libraries like MLJAR AutoML help automate these processes and make machine learning easier for beginners.
Getting Started with Machine Learning
Machine learning is becoming one of the most important technologies in modern software development. Fortunately, learning machine learning basics today is easier than ever. With powerful libraries, open datasets, and modern tools, anyone can start experimenting with machine learning projects. If you are starting your journey, focus on understanding the workflow, experimenting with simple algorithms, and building small projects. With practice and curiosity, you will quickly develop intuition about how machine learning models work. And once you start exploring real datasets, tools like MLJAR Studio, MLJAR AutoML, and MLJAR Mercury can help you build models faster and share results more easily. The most important step is simple: start working with data.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- Build chatbot to talk with your PostgreSQL database using Python and local LLM
- Build a ChatGPT-Style GIS App in a Jupyter Notebook with Python
- Private PyPI Server: How to Install Python Packages from a Custom Repository
- Essential Python Libraries for Data Science (2026 Guide)
- Statistics for Data Science: Essential Concepts
- Machine Learning vs AI vs Data Science: What’s the Difference? (Complete Guide)
- AI Ethics and Responsible Data Science: Building Fair and Private Machine Learning Systems
- Local vs Cloud Data Processing: Security, Privacy, and Private AI Workflows
- AutoResearch by Karpathy and the Future of Autonomous AI Research
- Complete Guide to Offline Data Analysis 2026