Essential Python Libraries for Data Science (2026 Guide)
Python has become the dominant language for data science largely because of its ecosystem. Today there are many powerful Python libraries for data science, each solving a specific problem in the workflow — from numerical computing and data processing to machine learning and model interpretation.
Over the past 15 years, the Python data science stack has grown step by step. It started with libraries for numerical computing, followed by tools for working with tabular data. Later came machine learning frameworks, powerful gradient boosting libraries, and deep learning systems. More recently, tools for model explainability, hyperparameter optimization, and automated machine learning have become part of the standard toolkit.
Each of these libraries was created to solve a particular challenge. Together they formed an ecosystem that is incredibly powerful, but sometimes also complex and fragmented. Data scientists often combine many different tools just to build a single machine learning pipeline.
In this article, we will walk through the most important Python libraries for data science and explain what role each of them plays. We will also discuss why modern data science increasingly benefits from integrated environments instead of many separate tools. Finally, we will look at how mljar-supervised provides transparent AutoML in Python and how MLJAR Studio represents a new generation of AI-native data science environments.
1. The Foundation Layer: Numerical Computing - NumPy
NumPy is one of the most important libraries in the Python data science ecosystem. It introduced the ndarray, a fast multidimensional array designed for numerical computing.
Today, almost every major data science library in Python relies on NumPy internally. For example, pandas stores data in NumPy arrays, scikit-learn works with NumPy matrices, and libraries such as XGBoost, TensorFlow, and PyTorch all use NumPy-like data structures.
Without NumPy, Python would not be competitive for numerical computing.
One of the main reasons NumPy is so fast is that it avoids slow Python loops. Instead, it performs operations directly on arrays using optimized C code. It also uses efficient memory layouts and vectorized operations that process many values at once.
For example, multiplying two arrays:
a * b
is much faster than looping through elements one by one in Python.
It is important to remember that NumPy is not a machine learning library. Think of it as the foundation layer that many other libraries build on top of.
2. The Tabular Data Revolution - pandas
While NumPy made numerical computing fast, pandas made working with real-world data much easier.
The key idea introduced by pandas is the DataFrame. It provides a simple and structured way to work with tabular data, similar to a spreadsheet or a database table.
Pandas also made it very easy to load data from common sources such as CSV files, Excel spreadsheets, and SQL databases. With just a few lines of code, analysts can load a dataset and start exploring it.
The library also simplified many everyday tasks like grouping data, joining datasets together, working with time series, handling missing values, and transforming columns efficiently.
These features helped turn Python into a practical tool for everyday data analysis.
Before pandas became popular, working with structured data in Python was much harder. Data cleaning often required manual loops, workflows were inconsistent, and it was difficult to reproduce transformations reliably.
After pandas, a much clearer workflow appeared. Many projects now follow a simple pipeline: load data from a file, convert it into a DataFrame, explore it, prepare features, and train a model.
This made exploratory data analysis much more systematic and reproducible.
However, even with pandas, many machine learning problems still come from data preparation mistakes rather than the models themselves. Common issues include data leakage, incorrect joins, misaligned time indexes, or mistakes in train/test splits.
Pandas makes data transformation fast and flexible, but building reliable data pipelines still requires careful work. This is one of the reasons why modern AI-assisted data science environments are becoming increasingly useful.
3. Machine Learning - scikit-learn
When people think about machine learning in Python, scikit-learn is usually the first library that comes to mind.
One of the biggest contributions of scikit-learn is its simple and consistent API. Most models follow the same pattern:
.fit()to train the model.predict()to generate predictions.transform()to modify data
Because of this design, learning one algorithm makes it much easier to use others.
Example:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score X_train, X_test, y_train, y_test = train_test_split(X, y) model = RandomForestClassifier(n_estimators=100) model.fit(X_train, y_train) predictions = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, predictions))
This clear and consistent structure helped make machine learning much more accessible.
Why scikit-learn remains essential
Even many advanced libraries follow the same interface. Libraries such as XGBoost, LightGBM, and CatBoost provide wrappers that behave like scikit-learn models.
Because of this, scikit-learn effectively defined the standard way to use machine learning in Python.
Limitations
While scikit-learn is extremely useful, it focuses mainly on providing individual algorithms. It does not automatically compare multiple models, generate experiment reports, or provide built-in explainability tools.
It also does not manage large hyperparameter searches or orchestrate full machine learning workflows.
In other words, scikit-learn provides excellent building blocks, but it does not manage the entire machine learning process.
Here is a more natural, friendly rewrite in simple English, keeping your meaning but smoothing the flow so it reads more like a human-written article.
4. The Gradient Boosting Era - XGBoost, LightGBM, CatBoost
In modern data science, gradient boosting libraries play a very important role, especially when working with tabular data.
Libraries such as XGBoost, LightGBM, and CatBoost are widely used in industry and machine learning competitions because they deliver excellent performance on structured datasets.
These models are powerful because they combine many decision trees into a single strong model. This approach allows them to capture complex patterns in data while remaining relatively efficient to train.
They also include many practical improvements such as fast training, support for GPU acceleration, and optimizations designed specifically for large datasets.
Example using LightGBM:
import lightgbm as lgb model = lgb.LGBMClassifier( n_estimators=300, learning_rate=0.05 ) model.fit(X_train, y_train) predictions = model.predict(X_test)
Why gradient boosting often beats deep learning on tabular data
In many real-world business problems, gradient boosting models perform better than deep learning models when the data is structured in tables.
One reason is that boosting algorithms work well even when the dataset is not extremely large. They also train faster and usually require much less infrastructure than neural networks.
Another advantage is interpretability. Tree-based models work very well with tools like SHAP, which help explain how individual features influence predictions.
Because of these advantages, gradient boosting algorithms have become a key component of many modern AutoML systems designed for tabular machine learning problems.
5. Deep Learning Frameworks - TensorFlow and PyTorch
Deep learning frameworks such as TensorFlow and PyTorch are used to build large neural networks. They power many modern AI systems, especially in areas like computer vision, natural language processing, and speech recognition.
These frameworks are designed to work efficiently with large datasets and complex models. They also support GPU acceleration, which allows training neural networks much faster than on standard CPUs.
Example in PyTorch:
import torch import torch.nn as nn model = nn.Sequential( nn.Linear(10, 64), nn.ReLU(), nn.Linear(64, 1) )
Deep learning can produce impressive results, but it also comes with additional complexity. Training neural networks usually requires powerful hardware, careful architecture design, and significant effort in tuning model parameters.
For many problems that involve structured business data, tree-based methods such as gradient boosting are often still a better choice. They are easier to train, require less infrastructure, and can deliver excellent performance.
6. Explainability and Optimization
SHAP – Model Interpretability
As machine learning models become more complex, understanding how they make predictions becomes increasingly important.
SHAP is a popular library used to explain model predictions. It is based on the concept of Shapley values from cooperative game theory. The idea is to measure how much each feature contributes to a prediction.
In simple terms, SHAP helps answer an important question:
Why did the model make this prediction?
Example:
import shap explainer = shap.Explainer(model, X_train) shap_values = explainer(X_test) shap.summary_plot(shap_values, X_test)
Explainability is important for several reasons. In many industries it is required for regulatory compliance. It also helps build trust with stakeholders and makes it easier to debug models and improve features.
By understanding how different variables influence predictions, data scientists can make machine learning systems more transparent and reliable.
Optuna – Hyperparameter Optimization
Another important part of building good machine learning models is hyperparameter tuning.
Libraries such as Optuna help automate this process. Instead of manually testing different configurations, Optuna searches for better hyperparameters automatically using efficient optimization techniques.
Example:
import optuna def objective(trial): max_depth = trial.suggest_int("max_depth", 2, 10) model = RandomForestClassifier(max_depth=max_depth) model.fit(X_train, y_train) return 1.0 - model.score(X_test, y_test) study = optuna.create_study(direction="minimize") study.optimize(objective, n_trials=30)
Optuna uses modern optimization strategies to explore the search space efficiently and can stop weak trials early, which saves time and computing resources.
Tools like this make machine learning more powerful, but they also add another layer of complexity to the workflow.
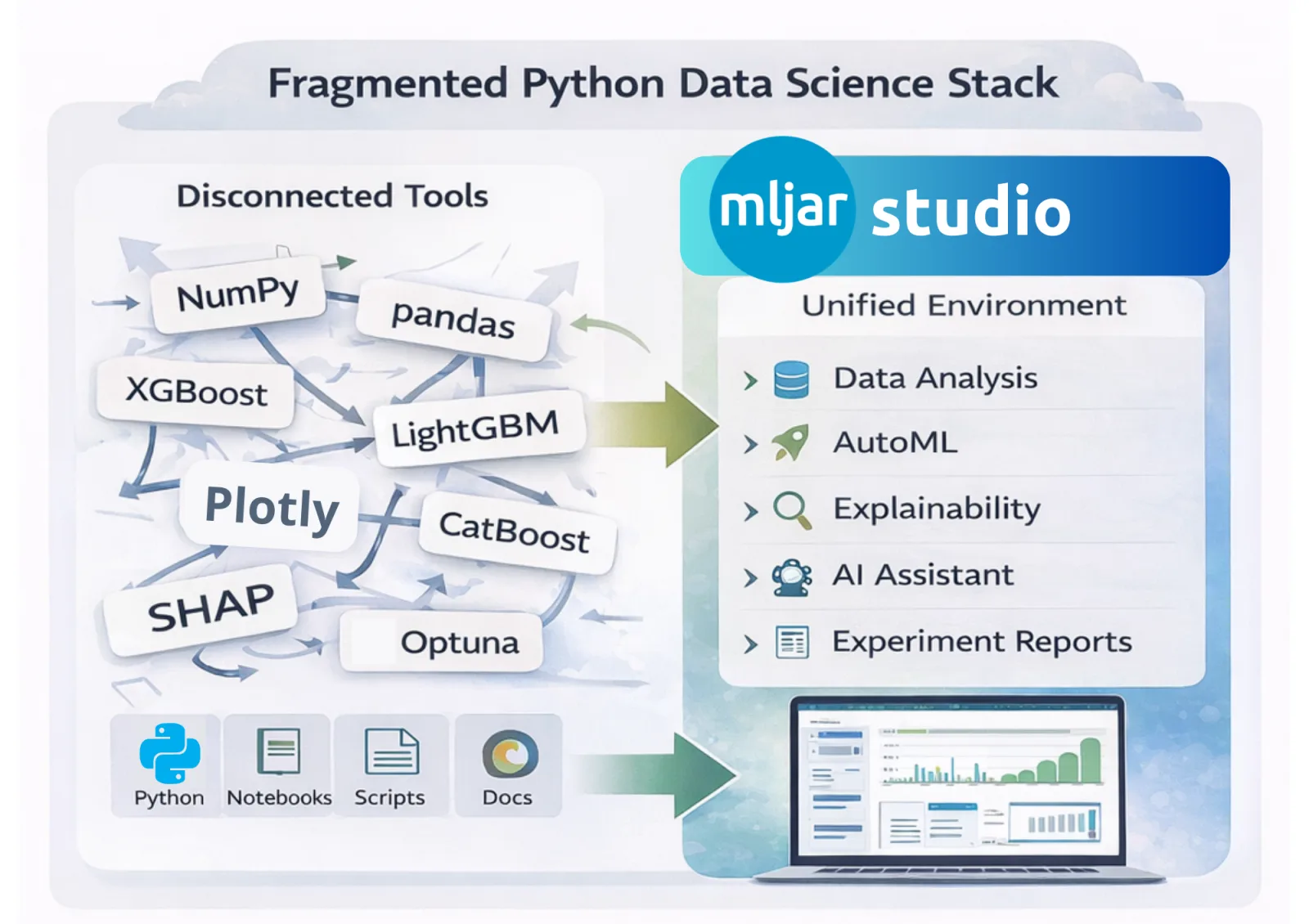
The Python Data Science Stack: Power and Fragmentation
A typical machine learning project today involves many different libraries. Data scientists often combine tools for numerical computing, data processing, modeling, optimization, visualization, and experiment tracking.
Each of these tools is excellent on its own. The challenge appears when they all need to work together in a real project.
Developers often end up writing large amounts of boilerplate code, repeating similar experiment logic across projects, and generating reports that are difficult to compare. Pipelines can also become hard to reproduce, especially when experiments evolve over time or involve many notebooks and scripts.
For new team members, this fragmented setup can make onboarding difficult because they need to understand many tools and conventions before they can contribute effectively.
The Python ecosystem for data science is incredibly powerful, but it is also naturally fragmented.
Transparent AutoML in Python
mljar-supervised is an automated machine learning library designed for tabular data.
Many AutoML tools behave like black boxes. They produce a model, but it is often difficult to understand what happened inside the training process. The goal of mljar-supervised is different. It focuses on transparency, so users can see how models are built and compared.
The library automatically trains multiple machine learning algorithms, tunes their hyperparameters, and evaluates their performance. At the same time, it generates clear Markdown reports that explain what was done and how the models performed.
The system supports many commonly used algorithms, including linear models, decision trees, random forests, extra trees, k-nearest neighbors, neural networks (MLP), and popular boosting libraries such as XGBoost, LightGBM, and CatBoost. It can also build ensemble and stacked ensemble models to improve performance.
Using the library is intentionally simple.
from supervised.automl import AutoML automl = AutoML(mode="Compete") automl.fit(X, y) predictions = automl.predict(X_test)
Behind this small piece of code, quite a lot is happening automatically. The system prepares the data, trains multiple models, tunes hyperparameters, evaluates their performance, and selects the best model. It also generates explainability artifacts such as SHAP-based visualizations.
In practice, mljar-supervised acts as a layer that connects many parts of the Python machine learning ecosystem and turns them into a structured and reproducible workflow.
Learn more:
- MLJAR AutoML website: mljar.com/automl
- MLJAR AutoML Documentation: supervised.mljar.com
MLJAR Studio – An AI-Native Data Science Environment
As the Python data science ecosystem grows, workflows often become harder to manage. Data scientists usually combine notebooks, machine learning libraries, visualization tools, experiment tracking systems, and AutoML frameworks. Each tool is powerful on its own, but putting everything together can quickly become complicated.
MLJAR Studio was created to simplify this workflow.
It is a desktop environment designed for data science that combines Python notebooks with automation and AI assistance. The idea is to keep the flexibility of Python while making everyday data science tasks faster and easier.
Inside MLJAR Studio you can write regular Python code, just like in a typical notebook. At the same time, the environment helps automate many repetitive steps such as data exploration, visualization, model training, and report generation.
MLJAR Studio brings several important components together in one place. It includes Python notebooks, the mljar-supervised AutoML engine, built-in SHAP explainability tools, and an AI Data Analyst agent that can help generate code and assist with data analysis.
The AI assistant can work with both cloud models and local LLMs, allowing users to run AI features directly on their own machine. This is especially useful when working with sensitive data or when an offline workflow is required.
Because everything is integrated, you can move from raw data to trained models and interpretable results without constantly switching between different tools.
MLJAR Studio also helps organize experiments. Instead of scattered scripts and notebooks, it creates structured experiment reports that make it easier to compare models and understand results.
In practice, MLJAR Studio acts as a modern data science workspace, where the Python ecosystem is integrated into a single environment.
Summary
Over the years, the Python data science ecosystem has grown into a powerful stack of libraries. Tools like NumPy provide fast numerical computing, while pandas makes it easy to work with tabular data. Libraries such as scikit-learn introduced a consistent way to build machine learning models, and boosting frameworks like XGBoost, LightGBM, and CatBoost became the standard for many tabular problems.
For deep learning tasks, frameworks such as TensorFlow and PyTorch allow researchers and engineers to build complex neural networks. At the same time, tools like SHAP help explain model predictions, and libraries such as Optuna automate hyperparameter tuning.
Together, these tools form a rich ecosystem that allows data scientists to solve a wide range of problems. The challenge is that combining many separate libraries can make workflows complex and difficult to manage.
This is where modern tools such as mljar-supervised and MLJAR Studio help simplify the process. By integrating many parts of the Python machine learning ecosystem, they make it easier to train models, understand results, and keep experiments organized.
Instead of spending time connecting many different tools, data scientists can focus on what really matters: understanding data, building reliable models, and delivering useful insights.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- New version of Mercury (3.0.0) - a framework for sharing discoveries
- Zbuduj lokalnego czata AI w Pythonie - Mercury + Bielik LLM krok po kroku
- Build chatbot to talk with your PostgreSQL database using Python and local LLM
- Build a ChatGPT-Style GIS App in a Jupyter Notebook with Python
- Private PyPI Server: How to Install Python Packages from a Custom Repository
- Statistics for Data Science: Essential Concepts
- Machine Learning Basics: Beginner’s Guide 2026
- Machine Learning vs AI vs Data Science: What’s the Difference? (Complete Guide)
- AI Ethics and Responsible Data Science: Building Fair and Private Machine Learning Systems
- Local vs Cloud Data Processing: Security, Privacy, and Private AI Workflows