Local vs Cloud Data Processing: Security, Privacy, and Private AI Workflows
Quick answer: Local workflows usually provide stronger control for sensitive datasets, while cloud workflows optimize collaboration and scale. This guide shows the tradeoffs.
1. Local vs. Cloud Data Processing: Security Comparison
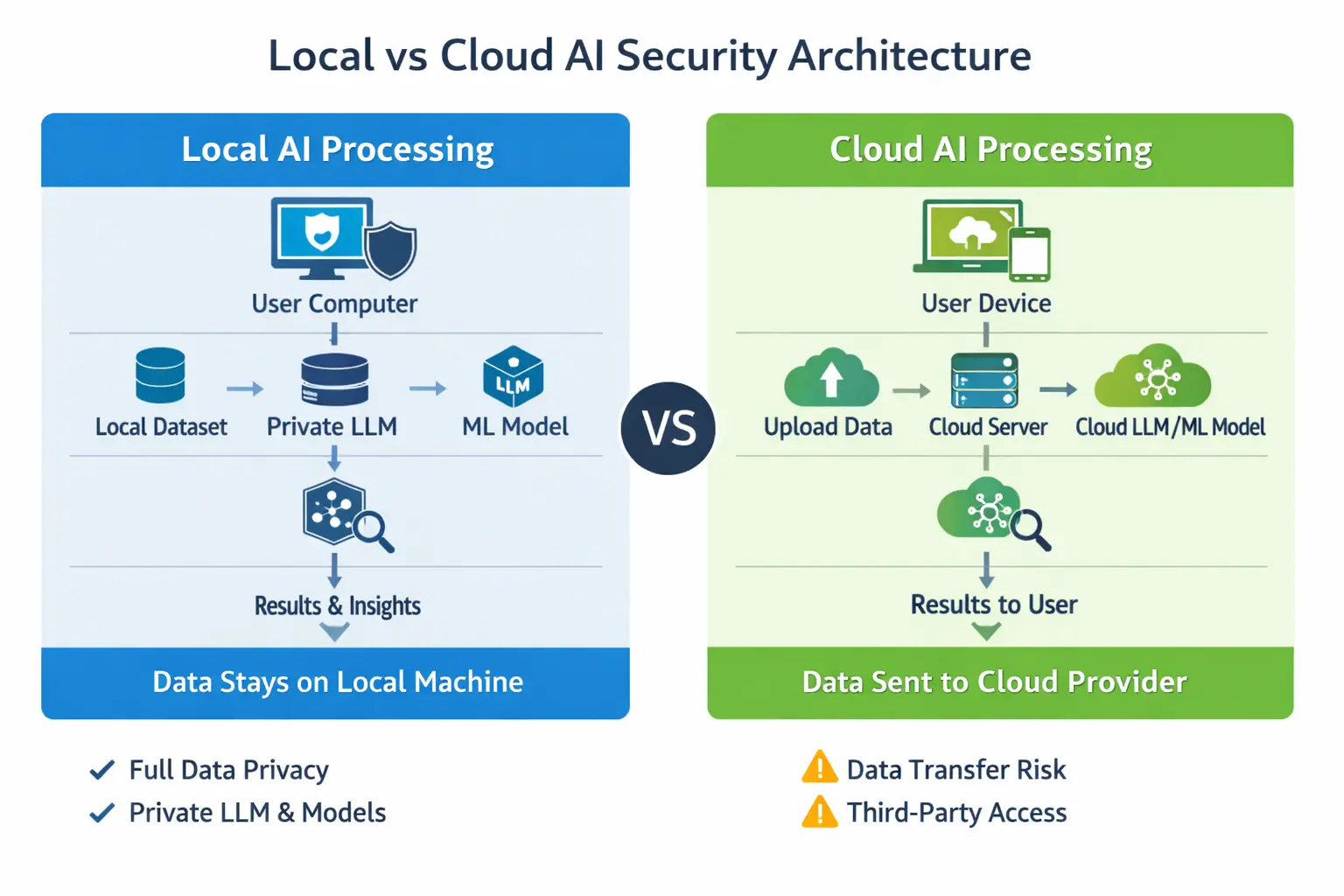
Local and cloud data processing represent two fundamentally different approaches to handling data in machine learning and data science workflows. In local data processing, datasets and models remain on a user’s computer or private infrastructure, providing full control over security and privacy. In cloud data processing, data is transmitted to external servers where computation happens on a scalable infrastructure managed by cloud providers. Choosing between these approaches depends on factors such as data sensitivity, security requirements, and infrastructure needs.
As organizations increasingly work with confidential datasets and AI assistants, many teams are exploring privacy-first solutions that allow machine learning and large language models (LLMs) to run locally without sending data to external services.
Data processing is at the heart of modern data science, machine learning, and artificial intelligence. Organizations analyze large datasets to extract insights, build predictive models, and automate decision-making. However, an important question arises when building data-driven systems:
Should data processing happen locally or in the cloud? Both approaches have advantages, but when it comes to security, privacy, and data control, the differences can be significant.
In this article, we compare local data processing vs cloud data processing, focusing on security risks, privacy considerations, and practical use cases for modern machine learning workflows. We also explore how tools such as MLJAR Studio enable private data processing with local machine learning and private LLMs.
2. What Is Local Data Processing?
Local data processing refers to performing computations directly on a local machine or private infrastructure, without sending data to external servers. This approach is often called on-premise data processing, offline data processing, or local machine learning.
In local processing workflows:
- datasets remain on the user's computer,
- models are trained locally,
- analysis tools run on the same machine as the data.
This approach is commonly used in industries where data confidentiality is critical, such as healthcare, finance, and government institutions. Private AI Workflow (Local)
3. What Is Cloud Data Processing?
Cloud data processing relies on remote infrastructure provided by cloud platforms. Data is uploaded to external servers where computation happens on a scalable infrastructure. Popular cloud-based workflows include:
- cloud machine learning platforms,
- hosted notebooks,
- remote data warehouses,
- cloud AI services.
Cloud processing allows organizations to scale computing resources easily, but it also introduces additional considerations regarding data security and privacy.
4. Security Comparison: Local vs Cloud Processing
The key differences between local and cloud processing become most apparent when comparing security and privacy.
| Factor | Local Processing | Cloud Processing |
|---|---|---|
| Data storage | Data remains on local machine | Data stored on remote servers |
| Data transfer | No external transmission required | Data must be uploaded |
| Privacy control | Full control over datasets | Depends on cloud provider policies |
| Security risk | Limited to local environment | Risk of network exposure |
| Compliance | Easier to maintain internal policies | Requires trust in external infrastructure |
Local data processing provides greater control over sensitive information, while cloud processing focuses on scalability and infrastructure management.
5. Privacy Risks in Cloud Data Processing
Cloud platforms provide powerful infrastructure, but sending sensitive data to external servers can introduce several risks, like data leaks caused by misconfigured storage, unauthorized access to datasets, regulatory compliance issues, or exposure of proprietary information. In some cases, organizations must comply with strict data protection laws such as GDPR in Europe, HIPAA in healthcare, financial industry regulations. For these environments, local data processing can provide a safer alternative.
6. Local AI and Private LLM Workflows
Another growing concern in modern AI workflows is the use of large language models (LLMs). Many AI assistants operate as cloud services where prompts and data are sent to external providers. This can raise serious privacy concerns when working with:
- confidential datasets,
- proprietary research,
- personal data,
- internal business information.
A solution is to run private LLMs locally. When models run locally, prompts remain on the local machine, sensitive data is not transmitted externally, and organizations maintain full control over information. This approach is becoming increasingly popular for secure machine learning workflows.
7. Privacy-First Data Science with MLJAR Studio
Privacy-first data science refers to building data analysis and machine learning systems where datasets remain under full user control and are not transmitted to external infrastructure. Modern tools are increasingly supporting privacy-first machine learning workflows. One example is MLJAR Studio, a desktop environment designed for data science and machine learning that allows data processing to happen directly on a local machine.
Unlike many cloud-based platforms, MLJAR Studio enables users to work with datasets without sending them to external infrastructure. This approach is particularly important for organizations that handle sensitive information and need full control over their data.
Private LLM vs Cloud AI APIs
Many AI assistants today operate through cloud APIs. When users send prompts to these systems, the prompts and often parts of the dataset are transmitted to external servers. For organizations working with confidential or regulated data, this can create privacy and compliance concerns.
Running private LLMs locally solves this problem. Local LLM workflows allow prompts to remain on the user's machine, sensitive data to stay private, and AI assistance to operate without external data transmission.
MLJAR Studio allows integrating private LLM assistants directly inside the desktop environment, enabling secure AI-powered workflows where both data analysis and AI assistance happen locally.
MLJAR Studio Hybrid AI Architecture
At the same time, MLJAR Studio supports hybrid AI workflows that combine local privacy with optional cloud scalability. In this approach:
- sensitive datasets can be processed locally,
- experimentation and model development happen on the user's machine,
- large-scale training tasks can optionally use cloud resources when additional computing power is required.
This hybrid architecture provides the best of both worlds: privacy-first development with the option to scale when needed. Unlike many cloud-only platforms, MLJAR Studio enables:
- fully offline data science workflows,
- local machine learning training,
- private dataset analysis
- integration with local AI assistants.
One of the most important features in the latest version is support for private LLMs. This means users can run language models locally inside the desktop environment without sending prompts or datasets to external services. For organizations working with sensitive data, MLJAR Studio offers a powerful alternative to cloud-based AI tools by allowing machine learning and AI workflows to run securely, locally, and under full user control.
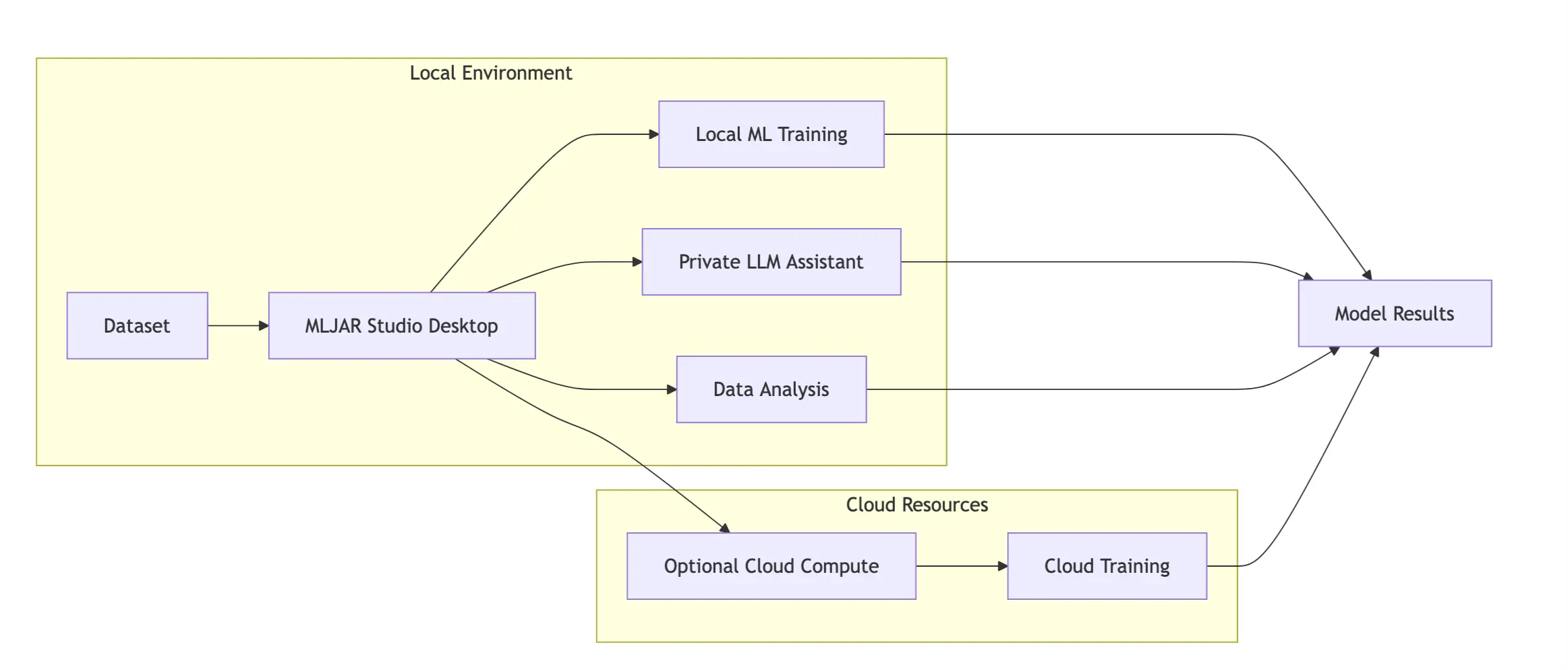
Unlike many cloud-based platforms, MLJAR Studio enables:
- fully offline data science workflows,
- local machine learning training,
- private dataset analysis,
- integration with local AI assistants.
One of the most important features in the latest version is support for private LLMs. This means users can run language models locally inside the desktop environment without sending prompts or data to external services. For organizations handling sensitive information, this offers a powerful alternative to cloud-based AI tools.
8. When Cloud Processing Makes Sense
Despite privacy concerns, cloud infrastructure still offers important advantages. Cloud-based workflows are particularly useful when extremely large datasets must be processed, distributed computing is required, teams collaborate across multiple locations, or scalable GPU infrastructure is needed. For many projects, organizations adopt hybrid workflows where sensitive data remains local while heavy computation runs in the cloud.
9. Best Practices for Secure Data Processing
Whether data is processed locally or in the cloud, responsible data science practices are essential. Some best practices include:
- minimizing data exposure,
- encrypting sensitive datasets,
- controlling access permissions,
- auditing machine learning workflows,
- monitoring data usage.
Tools that support local processing and privacy-first design can significantly reduce security risks.
Common Questions
Is local data processing more secure than cloud processing?
Local processing often provides greater control over sensitive data because datasets do not need to be transmitted to external servers.
What are the risks of cloud-based AI tools?
Cloud AI tools may require sending data to external infrastructure, which can raise privacy and compliance concerns.
Can machine learning workflows run completely offline?
Yes. Tools such as MLJAR Studio allow machine learning workflows to run entirely on a local machine without sending data to external services.
What is a private LLM?
A private LLM is a large language model that runs locally instead of through a cloud API. This ensures that prompts and datasets remain private.
Final Thoughts
Choosing between local and cloud data processing depends on the specific requirements of a project. Cloud infrastructure offers scalability and powerful computing resources, while local processing provides stronger control over sensitive information. For organizations that prioritize privacy, security, and full control over data, local workflows are becoming increasingly attractive. Tools like MLJAR Studio make it possible to run machine learning pipelines, analyze datasets, and even use AI assistants locally with private LLMs—without sending data outside the organization. As concerns about data security continue to grow, privacy-first data science environments may play an increasingly important role in the future of machine learning.
Explore next
Continue with practical guides, tutorials, and product workflows for Python, AutoML, and local AI data analysis.
- AI Data Analyst
Analyze local data with conversational AI support and notebook-based, reproducible Python workflows.
- AutoLab Experiments
Run autonomous ML experiments, track iterations, and inspect results in transparent notebook outputs.
- MLJAR AutoML
Learn how to train, compare, and explain tabular machine learning models with open-source automation.
- Machine learning tutorials
Step-by-step guides for beginners and practitioners working with Python, AutoML, and data workflows.
Run AI for Machine Learning — Fully Local
MLJAR Studio is a private AI Python notebook for data analysis and machine learning. Generate code with AI, run experiments locally, and keep full control over your workflow.
About the Author

Related Articles
- Essential Python Libraries for Data Science (2026 Guide)
- Statistics for Data Science: Essential Concepts
- Machine Learning Basics: Beginner’s Guide 2026
- Machine Learning vs AI vs Data Science: What’s the Difference? (Complete Guide)
- AI Ethics and Responsible Data Science: Building Fair and Private Machine Learning Systems
- AutoResearch by Karpathy and the Future of Autonomous AI Research
- Complete Guide to Offline Data Analysis 2026
- Data Analysis Software for Pharmaceutical Research
- AI Coding Assistants for Data Science: Complete 2026 Comparison
- Machine Learning for Humans and LLMs: Structured AutoML Reports in Python