AutoResearch by Karpathy and the Future of Autonomous AI Research
Recently, Andrej Karpathy introduced AutoResearch, a small open-source project that explores an interesting idea: using AI agents to run machine learning experiments automatically. Instead of manually modifying code, training models, and evaluating results, an AI system can iteratively perform these steps and search for better solutions. The project demonstrates how large language models can participate directly in the experimental loop of machine learning research.
As the author of MLJAR-supervised, an open-source automated machine learning framework, I find this direction particularly interesting. Machine learning development usually involves many repeated experiments: changing features, adjusting models, testing validation strategies, and comparing metrics. Tools that allow AI systems to perform these iterations automatically could significantly accelerate the process of developing machine learning solutions.
In this article, I explain how AutoResearch by Andrej Karpathy works and why the idea of autonomous experimentation is attracting attention. I will also show how a similar concept can be applied to practical machine learning workflows using AutoLab experiments in MLJAR Studio, where AI agents can iteratively build and evaluate solutions while keeping the entire process transparent through notebooks and experiment dashboards.
What is AutoResearch by Andrej Karpathy?
AutoResearch is a small open-source project created by Andrej Karpathy that explores the idea of autonomous machine learning experimentation. The goal of the project is to demonstrate how an AI agent can participate directly in the research process by modifying code, running experiments, evaluating results, and repeating the process to improve performance. Instead of a human researcher manually testing many ideas, the system allows an AI model to iteratively explore possible solutions.
The project is intentionally minimal and designed mainly as a research prototype. It contains a simple training setup, instructions for an AI agent, and an experimental loop where the agent proposes changes to the machine learning code. After each change, a short training run is executed and the resulting metric is evaluated. If the modification improves the result, the system keeps the change and continues searching for further improvements.
This approach reflects how many machine learning experiments are performed in practice. Data scientists often follow a cycle of trying a new idea, running an experiment, evaluating the metric, and adjusting the approach based on the results. AutoResearch attempts to automate this cycle so that AI agents can perform a large number of experiments automatically, potentially exploring solutions faster than a human working manually.
How AutoResearch Works
AutoResearch is designed as a minimal experimental framework that demonstrates how an AI agent can participate in the machine learning research loop. Instead of a human manually modifying code and running experiments, an AI model proposes changes to the training program, executes experiments, and evaluates the results.
At the core of the system is a simple iterative process. The AI agent analyzes the current training setup, suggests a modification, runs an experiment, and checks whether the modification improves the evaluation metric. This process repeats many times, allowing the system to explore different model configurations or training strategies.
Conceptually, the workflow looks like this:
AI agent proposes modification ↓ Update training code ↓ Run training experiment ↓ Evaluate metric ↓ Keep improvement or try another change ↓ Repeat
In the AutoResearch project, the environment typically contains a training script that defines how a model is trained and evaluated. The AI agent is allowed to modify parts of this code in order to test new ideas. For example, it may adjust model parameters, modify the architecture, change optimization settings, or introduce different preprocessing steps.
After each modification, the system runs a short experiment and measures the resulting performance using a predefined metric. If the change improves the result, it becomes part of the new baseline configuration. If it does not help, the agent can try a different modification in the next iteration.
Because the experiments can be short and automated, the system can run many trials in sequence. This allows the AI agent to explore a large number of potential solutions without requiring constant human supervision. The goal is not to replace human researchers, but to automate repetitive experimentation and help discover promising ideas faster.
Limitations of AutoResearch
The idea behind AutoResearch is powerful, but the project itself is intentionally minimal. It was created as a compact research prototype to demonstrate the concept of autonomous experimentation rather than a full platform for machine learning development.
One limitation is that the system requires direct interaction with code. Users must prepare the training environment, define the experiment setup, and configure the files that the AI agent can modify. This approach works well for researchers who are comfortable working with Python scripts, but it may be less accessible for data scientists who prefer structured workflows or graphical tools.
Another challenge is experiment transparency and organization. In AutoResearch, experiments are executed as part of a continuous loop, and the results are primarily observed through logs and metrics. While this is sufficient for testing ideas, it can make it harder to track individual experiments, compare results, or inspect the reasoning behind specific changes.
Finally, monitoring the overall progress of experiments can be limited. When running many iterations, users may want to see which trials were performed, what configurations were tested, and which experiment produced the best result. In more complex machine learning workflows, having a clear record of experiments and their outputs can be very helpful for analysis and reproducibility.
These limitations do not reduce the value of the AutoResearch project. Instead, they highlight that the repository focuses on demonstrating the concept of AI-driven experimentation rather than providing a complete workflow for machine learning practitioners. This raises an interesting question: how could a similar idea be implemented in a way that integrates naturally into everyday machine learning development?
A Practical Approach: AutoLab Experiments
The idea behind AutoResearch — allowing AI agents to run machine learning experiments automatically — is very compelling. However, applying this concept in everyday machine learning work requires a workflow that helps users define the problem, monitor experiments, and inspect the results.
Inspired by this idea, we implemented a similar concept in MLJAR Studio called AutoLab experiments. The goal of AutoLab is to make autonomous experimentation accessible in a structured machine learning environment while keeping the process transparent and reproducible.
Instead of editing training scripts directly, the workflow begins with a structured description of the machine learning task. The user fills a form that defines key elements of the experiment, such as the dataset, the evaluation metric, the validation strategy, and the number of trials that should be performed. The user can also provide additional context, such as which features should be used or whether feature engineering and model interpretation should be explored.
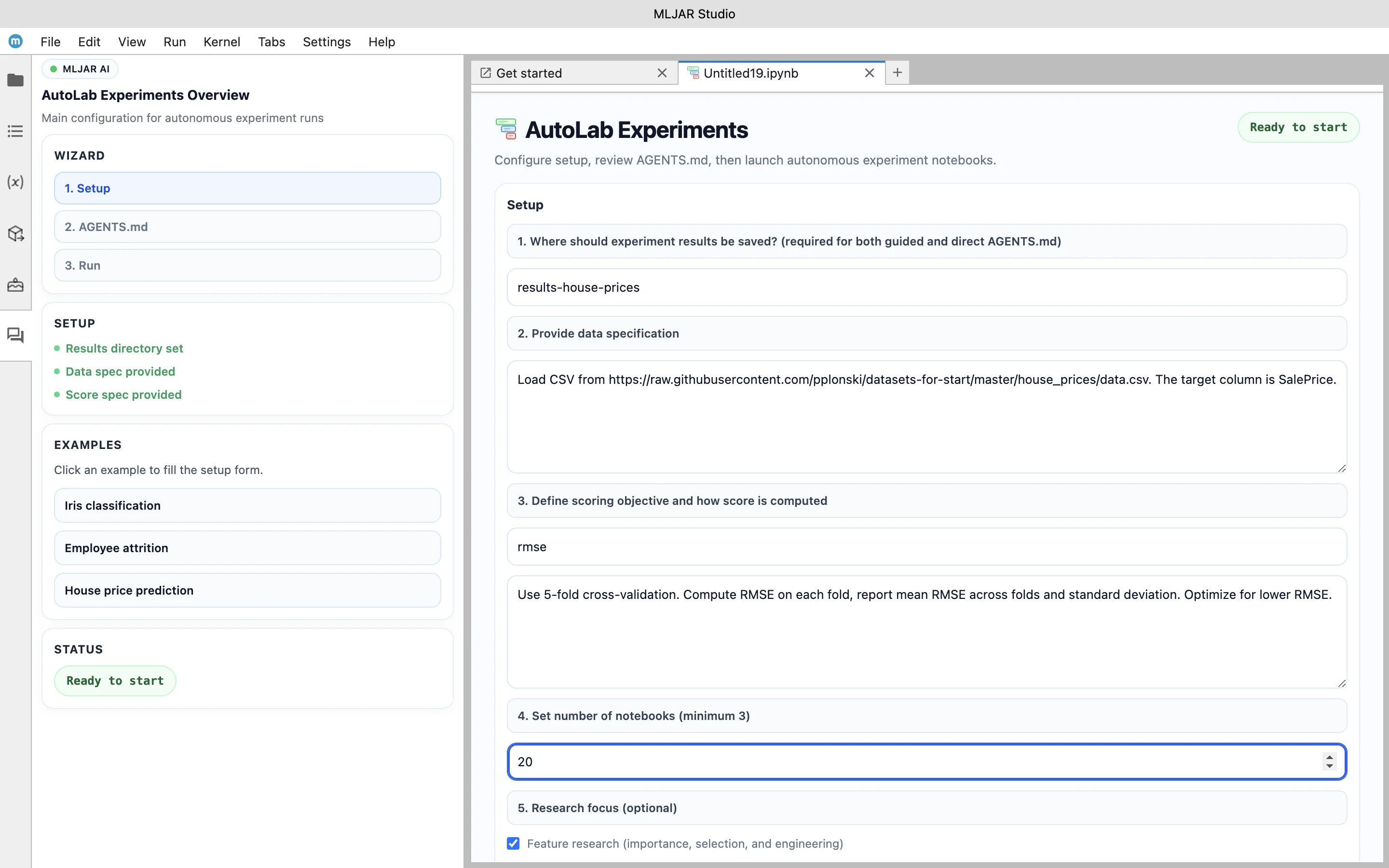
From this information, MLJAR Studio generates a file called AGENTS.md. This file contains instructions that describe the machine learning problem and the objectives for the AI agents. It serves as a specification that guides how the agents should approach the experiment and what metric they should optimize.
Once the instructions are generated and reviewed, the user can start the AutoLab experiment. AI agents then begin iteratively constructing and evaluating solutions to the machine learning problem. Each trial represents a proposed approach, which may include changes in model configuration, feature processing, or training strategy.
One important design decision in AutoLab is transparency. Every experiment trial is saved as a Jupyter Notebook that contains the full plan, the generated code, and the resulting outputs. This allows users to inspect how the solution was constructed and understand the reasoning behind each experiment.
In addition, MLJAR Studio provides a dashboard where users can monitor the progress of the experiment. The dashboard displays information such as the number of completed trials, the current best metric, and the overall execution status. This makes it easier to observe how the system explores different solutions over time.
Conceptually, the workflow looks like this:
Describe ML problem ↓ Generate AGENTS.md instructions ↓ Start AutoLab experiment ↓ AI agents run trials ↓ Solutions saved as notebooks ↓ Monitor progress in dashboard
By combining structured problem definition, autonomous experimentation, and transparent results, AutoLab experiments attempt to bring the idea of AI-driven research closer to practical machine learning development.
Comparing AutoResearch and AutoLab
Both AutoResearch and AutoLab explore the idea of autonomous machine learning experimentation, where AI agents participate in the process of testing and improving machine learning solutions. However, the two approaches focus on different goals and levels of abstraction.
AutoResearch, created by Andrej Karpathy, is designed as a minimal research prototype. Its main purpose is to demonstrate how an AI agent can modify training code, run experiments, and iteratively search for improvements. The repository intentionally keeps the system small and simple so that the underlying idea of autonomous experimentation is easy to understand.
AutoLab experiments, on the other hand, aim to integrate a similar idea into a structured machine learning workflow. Instead of modifying scripts directly, users describe the machine learning problem through a form, which is then converted into instructions for AI agents. The system manages experiments, records results, and stores each trial as a notebook that can be inspected later.
The differences between the two approaches can be summarized as follows:
| Aspect | AutoResearch | AutoLab |
|---|---|---|
| Primary goal | Demonstrate autonomous research concept | Provide a practical experimentation workflow |
| Interface | Code-based setup | Structured form describing the ML problem |
| Experiment outputs | Logs and experiment results | Full notebooks with code, outputs, and explanations |
| Experiment tracking | Manual inspection | Dashboard showing experiment progress |
| Target users | Researchers and developers | Data scientists and ML practitioners |
These differences reflect two complementary perspectives on the same idea. AutoResearch shows how AI agents can participate in the experimental loop of machine learning research. AutoLab experiments explore how similar concepts can be integrated into tools designed for everyday machine learning development.
Both approaches highlight a broader trend: the growing role of AI systems in assisting with experimentation, model development, and the exploration of new machine learning solutions.
Example: Predicting House Prices with AutoLab
To better understand how autonomous experiments work in practice, let’s walk through a concrete example: predicting house prices from a tabular dataset.
The task is to build a regression model that predicts the SalePrice of a house based on features such as size, number of rooms, and location. This type of problem is a common benchmark in machine learning because it requires a combination of feature engineering, proper validation, and model selection.
Defining the Problem
The AutoLab workflow begins with describing the machine learning problem in a structured way. Instead of writing training scripts, the user defines the experiment using a form.
In this example, the dataset is loaded from a CSV file, the target variable is set to SalePrice, and the evaluation metric is defined as RMSE. The validation strategy uses 5-fold cross-validation, and the experiment is configured to perform multiple trials. Additional options enable feature research and model explainability, which will be part of the generated results.
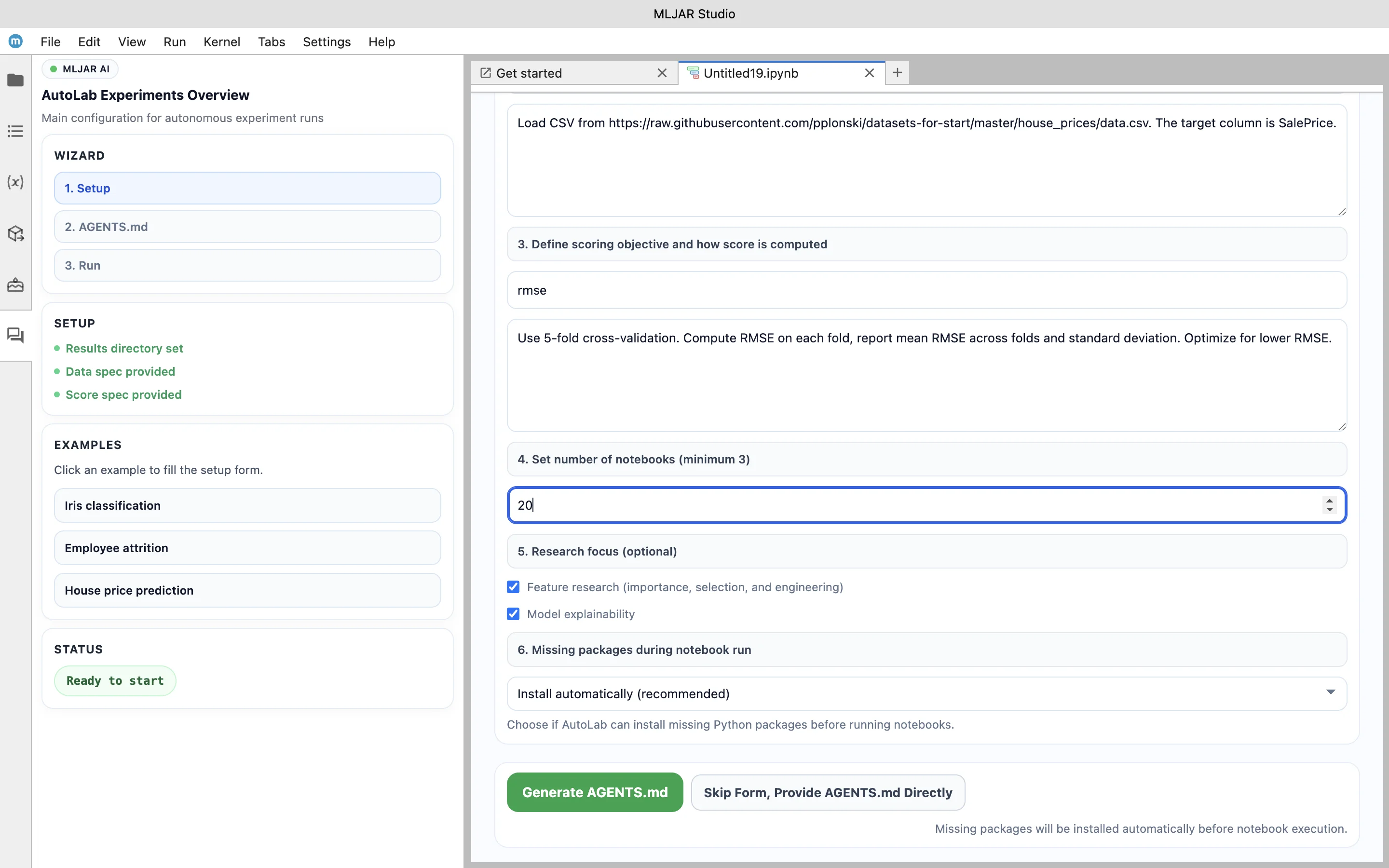
This step defines the entire experiment in a reproducible way and provides all the necessary context for the AI agents.
Generating AGENTS.md Instructions
Once the problem is defined, MLJAR Studio generates an AGENTS.md file that describes the experiment in detail. This file acts as a specification for the AI agents and defines how they should approach the task.
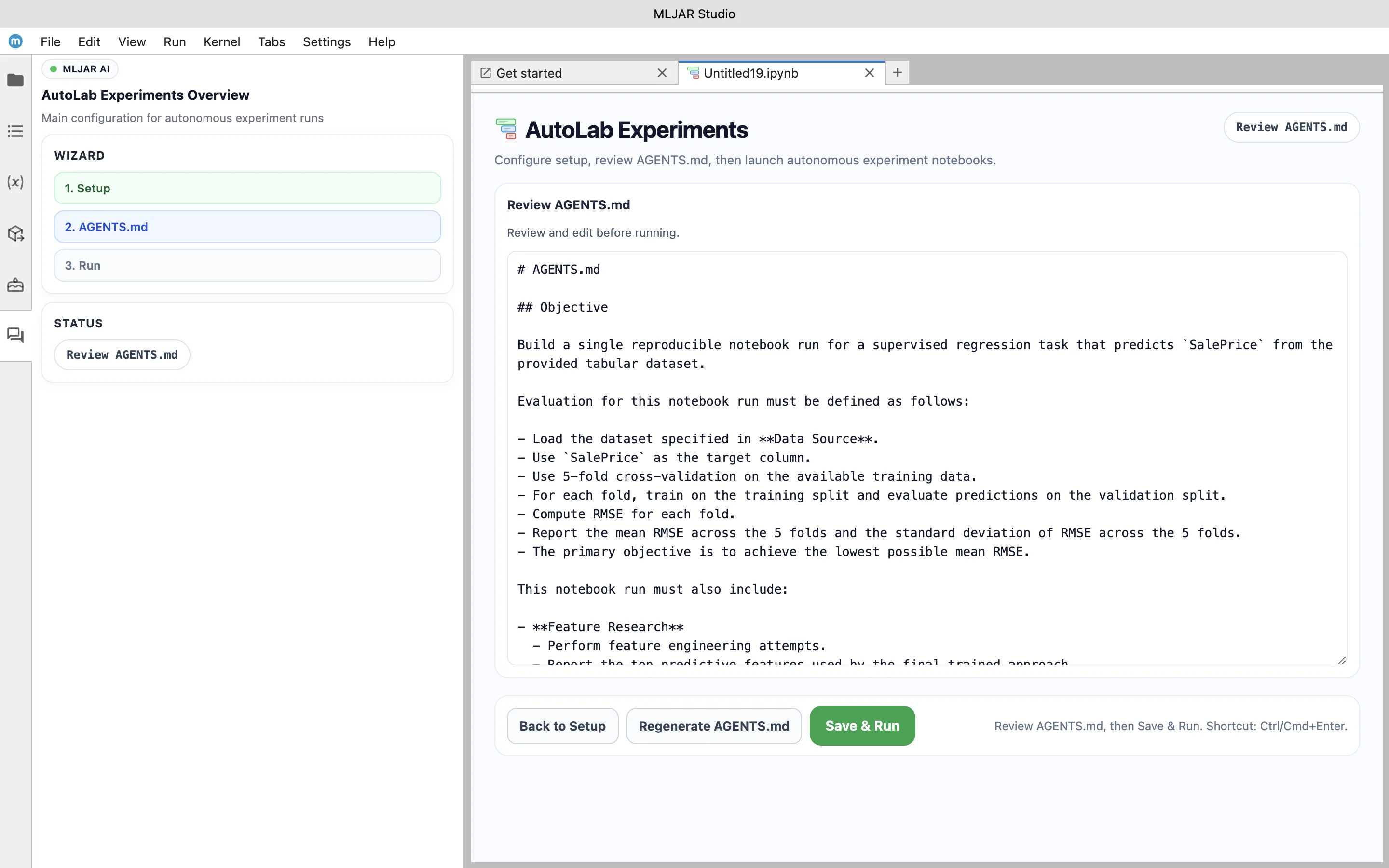
The instructions include the objective of minimizing RMSE using cross-validation, as well as requirements for feature engineering and model explainability. It also defines how results should be reported and what artifacts should be generated.
In this example, the agents are required not only to build a predictive model but also to analyze features and explain the behavior of the final model. This makes the experiment more than just model training — it becomes a structured research process.
Running Autonomous Experiments
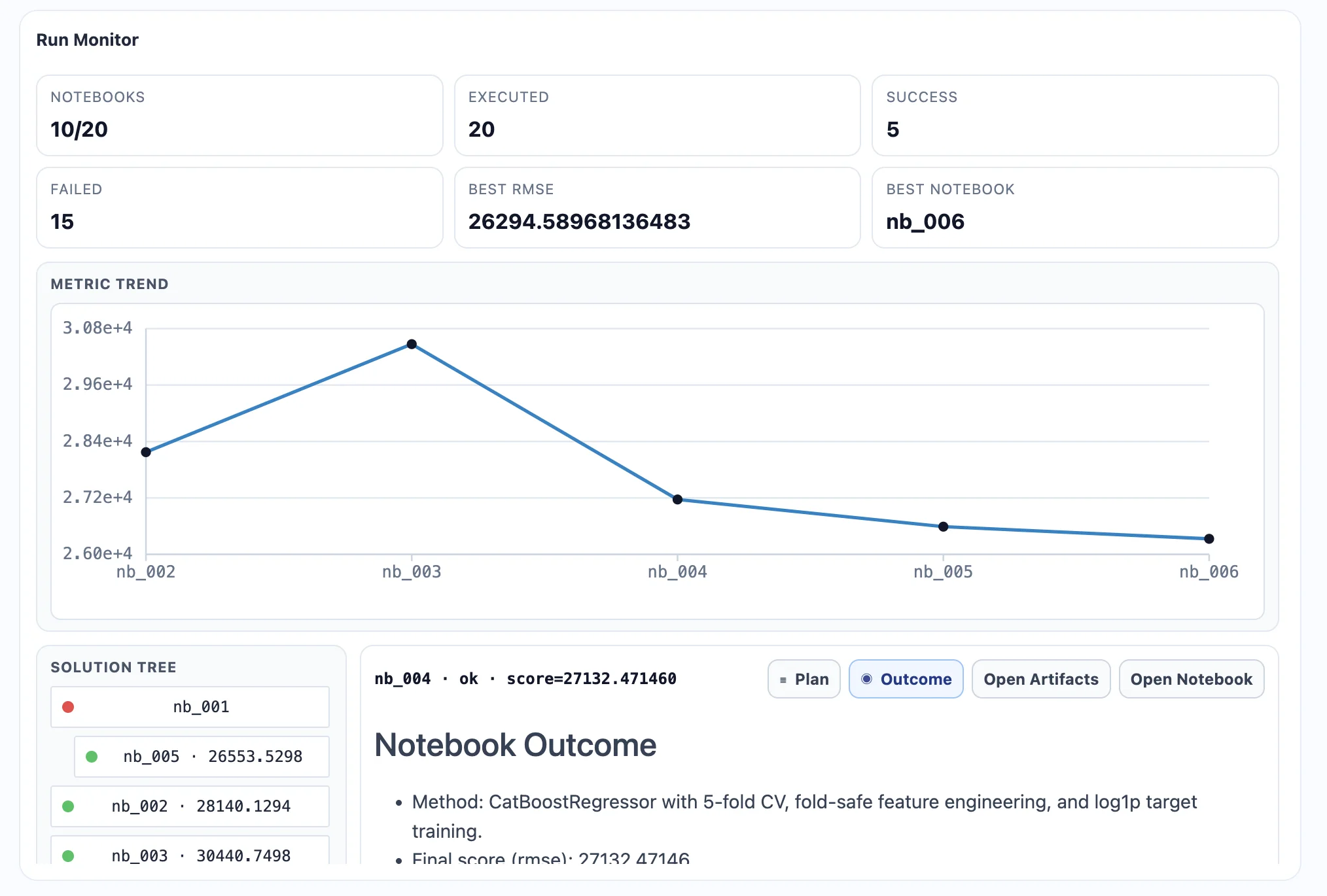
After reviewing the instructions, the experiment can be started. At the beginning, the dashboard is empty, as no trials have been executed yet.
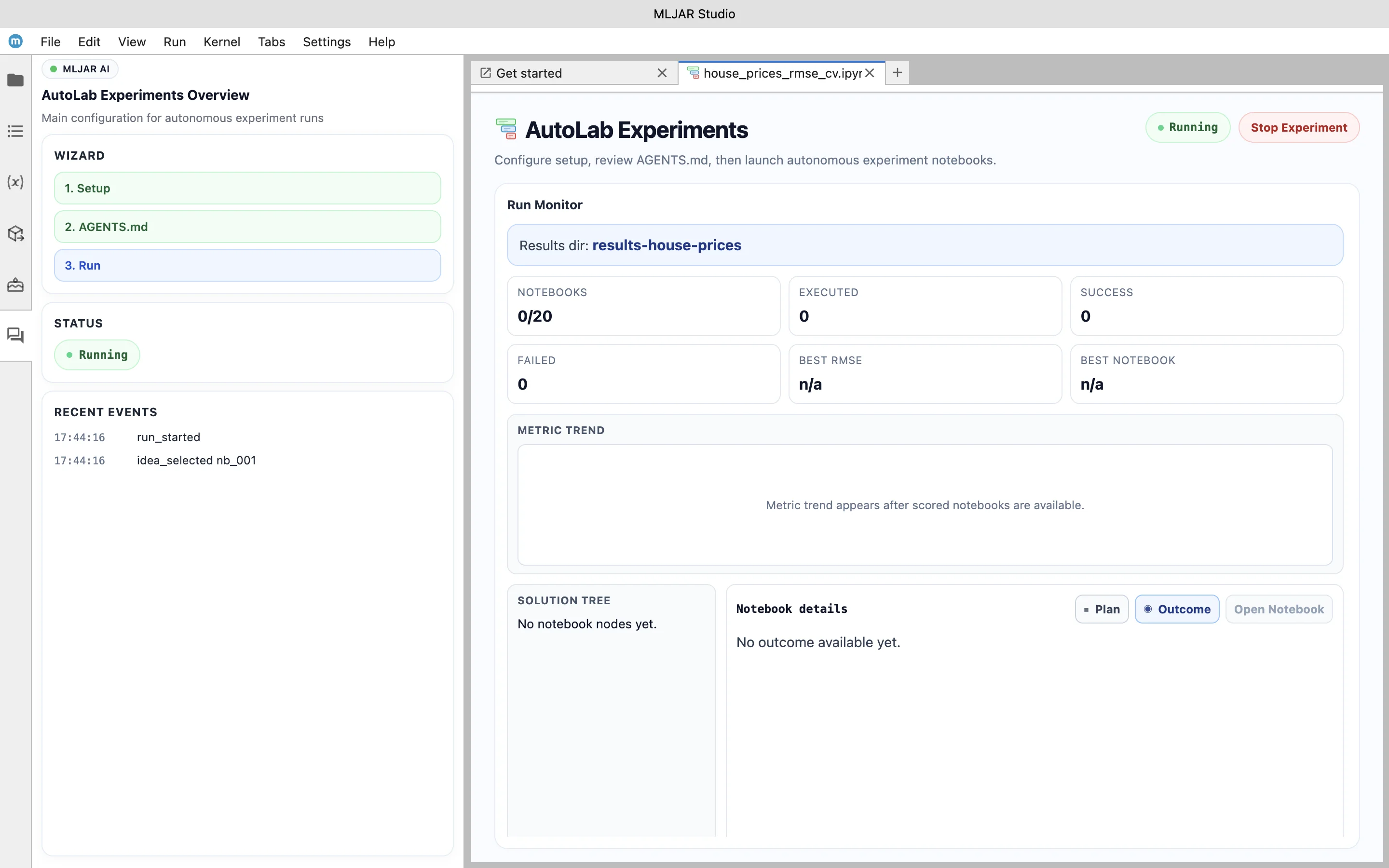
As the experiment progresses, AI agents begin running trials and exploring different approaches. Each trial represents a new attempt to solve the problem, potentially using different models, preprocessing strategies, or feature transformations.
The dashboard updates in real time, showing how many trials have been completed, what the current best score is, and how the experiment is evolving. This makes it easy to observe how the system searches for better solutions over time.
Inspecting Generated Notebooks
Each trial performed by the AI agents is saved as a Jupyter Notebook. This is one of the key design choices in AutoLab, because it ensures that every experiment is transparent and reproducible.
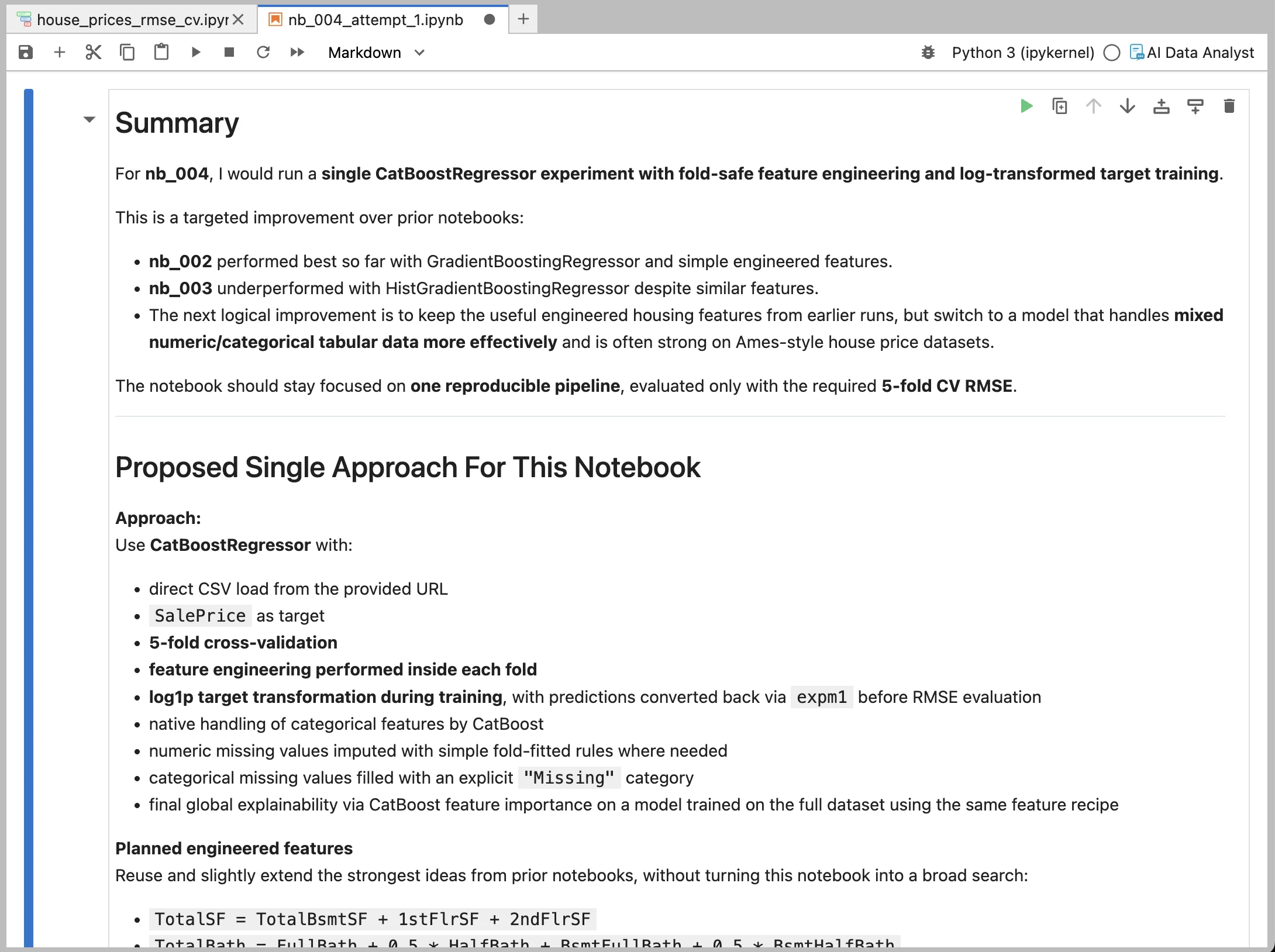
The notebook contains the full experiment plan written in markdown, the generated Python code, and all outputs produced during training and evaluation. This includes metrics, plots, and intermediate results.
Instead of treating the experiment as a black box, the user can inspect exactly how the solution was constructed and understand the reasoning behind each step.
Feature Research and Explainability
In this example, the experiment also includes feature research and model explainability. The system generates additional artifacts that describe which features were most important and how they influenced the predictions.
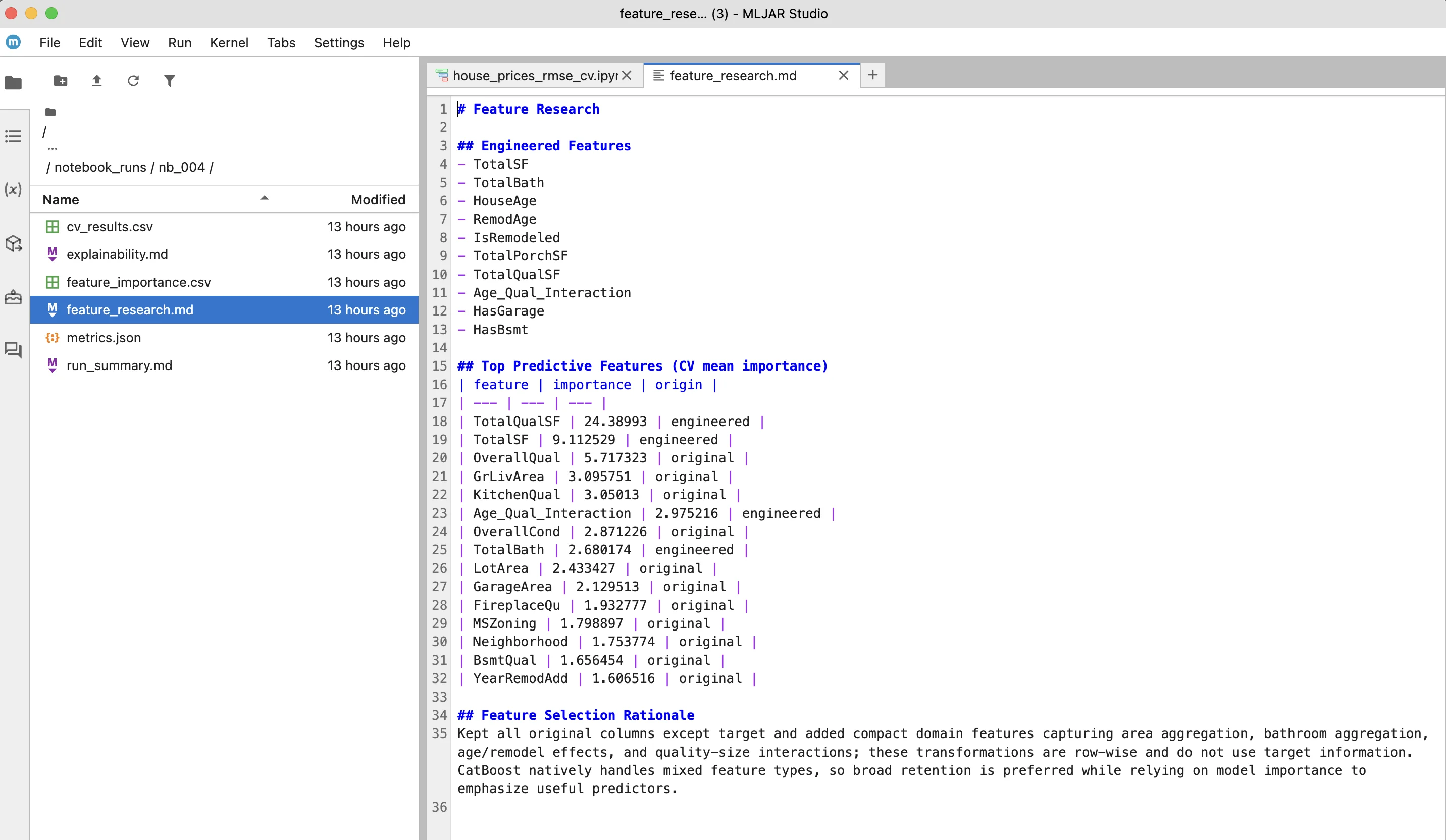
The results include both original features and newly engineered ones, along with a short explanation of why certain features were selected or removed. The model explainability output provides insight into the main drivers of predictions, helping to understand how the model makes decisions.
Why This Example Matters
This example shows how the idea behind AutoResearch by Andrej Karpathy can be applied in a practical machine learning workflow.
Instead of manually running multiple experiments, the AI agents explore different approaches automatically, evaluate their performance, and document the results. At the same time, the entire process remains visible through notebooks and dashboards, which makes it possible to understand and reproduce every step.
In this way, autonomous experimentation becomes not only a way to speed up model development, but also a structured and transparent process that supports better decision-making in machine learning projects.
The Future of Autonomous Machine Learning Experiments
The idea behind AutoResearch by Andrej Karpathy points toward an important shift in how machine learning systems are developed. Instead of manually designing and testing every experiment, we are starting to see systems where AI agents participate directly in the experimental process.
This does not mean replacing data scientists. Rather, it changes their role. Instead of focusing on running individual experiments, practitioners can focus on defining the problem, selecting the right objectives, and interpreting results. The experimental loop — trying variations, training models, and evaluating metrics — can increasingly be automated.
This direction is closely related to the evolution of AutoML. Traditional AutoML systems automate model selection and hyperparameter tuning. Systems like AutoResearch and AutoLab extend this idea further by allowing AI agents to explore not only parameters, but also feature engineering strategies, training procedures, and even parts of the modeling logic.
At the same time, transparency remains essential. One of the key challenges in autonomous systems is ensuring that results can be understood, verified, and reproduced. Approaches that store experiments as notebooks and generate structured artifacts help maintain this transparency, making it possible to inspect how solutions were constructed and why they work.
Looking forward, we can expect more tools that combine:
- structured problem definitions
- autonomous experimentation
- reproducible outputs
- human-readable explanations
These systems may become a standard part of machine learning workflows, especially for tasks that require exploring many possible solutions.
AutoResearch demonstrates what is possible with a minimal setup. AutoLab experiments show how similar ideas can be integrated into practical tools for everyday machine learning work. Together, they illustrate a broader trend: moving from manually driven experimentation toward AI-assisted research and development.
Autonomous experimentation is still evolving, but it is already changing how we approach machine learning problems.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- Statistics for Data Science: Essential Concepts
- Machine Learning Basics: Beginner’s Guide 2026
- Machine Learning vs AI vs Data Science: What’s the Difference? (Complete Guide)
- AI Ethics and Responsible Data Science: Building Fair and Private Machine Learning Systems
- Local vs Cloud Data Processing: Security, Privacy, and Private AI Workflows
- Complete Guide to Offline Data Analysis 2026
- Data Analysis Software for Pharmaceutical Research
- AI Coding Assistants for Data Science: Complete 2026 Comparison
- Machine Learning for Humans and LLMs: Structured AutoML Reports in Python
- AI in Healthcare without breaking HIPAA (MLJAR Studio guide)