The next-generation of AutoML frameworks
 Automated Machine Learning (AutoML) is a process of building a complete Machine Learning pipeline automatically, without (or with minimal) human help. The AutoML solutions are quite new, with the first research papers from 2013 (Auto-Weka), 2015 (Auto-sklearn), and 2016 (TPOT). Currently, there are several AutoML open-source frameworks and commercial platforms available that can work with a variety of data. There is worth mentioning such open-source solutions like AutoGluon, H2O, or MLJAR AutoML.
Automated Machine Learning (AutoML) is a process of building a complete Machine Learning pipeline automatically, without (or with minimal) human help. The AutoML solutions are quite new, with the first research papers from 2013 (Auto-Weka), 2015 (Auto-sklearn), and 2016 (TPOT). Currently, there are several AutoML open-source frameworks and commercial platforms available that can work with a variety of data. There is worth mentioning such open-source solutions like AutoGluon, H2O, or MLJAR AutoML.
The main goal of the AutoML framework was to find the best possible ML pipeline under the selected time budget. For its purpose, AutoML frameworks were training many different ML algorithms and tune their hyper-parameters. The improvements in the performance can be obtained by increasing the number of algorithms and checked hyper-parameters settings, which means longer computation time. But is the performance of the ML pipeline the only goal of the analysis?
The AutoML users
The goal of AutoML analysis depends on the user. Based on the authors’ observations, there are several types of AutoML users:
-
Software engineers well understand the Machine Learning theory but have a lack of experience in building ML pipelines. They are looking for AutoML with a simple API that can be easily integrated into their system. They need the best ML pipeline but under the constrain for prediction time on a single sample. They don’t want to build a stacked ensemble with several layers of models that need a lot of time to compute prediction for a single sample. They are looking for the ML model that computes prediction in milliseconds to be easily used in the REST API service.
-
Researchers and citizen data scientists are in the second group of AutoML users. They well understand the Machine Learning theory but are not proficient in coding. They are looking for a low-code solution that can be used to check many different algorithm combinations easily. They would like to understand as much as possible about their data. For example, which features are the most important, or are there any new feature combinations with predictive power (golden features).
-
The next group of users is seasoned data scientists. They are using AutoML for initial data understanding and quick prototyping. They would like to solve business needs quickly. They are looking for unique insights about data that can be used to improve company operations - the ML explainability is very important to them. They often need a simple Machine Learning model that can be easily interpreted and explained to other stakeholders (for example single Decision Tree with extracted text rules).
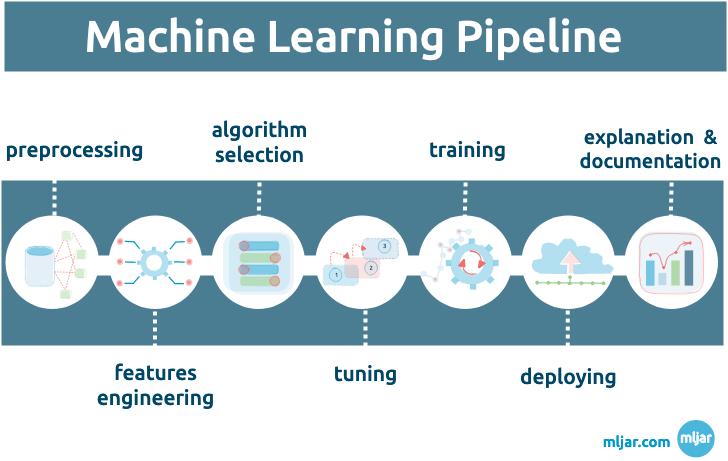
The next-generation of AutoML
The AutoML needs to be multipurpose to fill most of the users’ needs. That’s why AutoML frameworks often introduce the switchable mode of work. We will show you how it works in MLJAR AutoML (authors contribute to this open-source project). The MLJAR AutoML can work in four modes:
Explainthat is perfect for initial data understanding. It splits data into 80/20 train and test sets. It trains algorithms like Baseline, Decision Tree, Linear, Random Forest, Xgboost, Neural Network, and Ensemble. It doesn’t perform hyperparameters tuning. It uses default hyperparameters values. In this mode, full explanations are computed for models: decision tree visualization, decision tree rules extraction, feature importance, SHAP dependency plots, SHAP decision plots.Performmode for training production-ready ML pipelines. It uses 5-fold cross-validation and tune algorithms like Random Forest, Xgboost, LightGBM, CatBoost, Neural Network, and Ensemble. It searches for the ML pipeline with prediction time for a single sample under 500 milliseconds (which can be set as an argument).Competemode for searching the best performing ML models under selected time budget. It is using an adjusted validation strategy that depends on dataset size. It highly tunes algorithms. Additionally, it applies advanced feature engineering techniques, like golden features, feature selection, k-means features.Optunathe mode for tuning ML models without a hard time limit for AutoML training. It is using the Optuna framework for hyperparameters tuning. It provides well-performing models, but the computational time can be large.
''' MLJAR AutoML can work in 4 modes: - Explain - Perform - Compete - Optuna ''' # training in Explain mode, perfect for data exploration automl = AutoML(mode="Explain") automl.fit(X, y) # training in Perform mode, perfect for production-ready systems # AutoML trained for 4 hours automl = AutoML(mode="Perform", total_time_limit=4*3600) automl.fit(X, y) # training in Compete mode, perfect for high performing ML pipelines automl = AutoML(mode="Compete", total_time_limit=4*3600) automl.fit(X, y) # training in Optuna mode, highly tune selected algorithm automl = AutoML( mode="Optuna", algorithms=["CatBoost", "LightGBM", "Xgboost"], optuna_time_budget=3600, total_time_limit=8*3600, eval_metric="f1" ) automl.fit(X, y)
The Automatic Documentation and Notebook support
The AutoML can not be a black-box. The user wants to check the internals of each trained ML configuration in the pipeline. In the MLJAR AutoML the each trained model has its own README.md markdown file with documentation. The Markdown files can be displayed in the code IDE like Visual Studio Code or code repositories like GitHub.
What is more, the markdown documentation can be easily translated into raw HTML and displayed in Python Notebook as an interactive report (example notebook with AutoML report -> link).
The AutoML framework comparison on Kaggle datasets
We compared AutoML frameworks on 10 tabular datasets from Kaggle’s past competitions. The datasets used in the comparison are described in the table below.
| Competition | Task | Metric | Year | Teams | Rows | Columns |
|---|---|---|---|---|---|---|
| Mercedes-Benz Greener Manufacturing | regression | R2 | 2017 | 3,823 | 4,209 | 377 |
| Santander Value Prediction Challenge | regression | RMSLE | 2019 | 4,463 | 4,459 | 4,992 |
| Allstate Claims Severity | regression | MAE | 2017 | 3,045 | 180,000 | 131 |
| BNP-Paribas Cardif Claims Management | binary | log-loss | 2016 | 2,920 | 110,000 | 132 |
| Santander Customer Transaction Prediction | binary | AUC | 2019 | 8,751 | 220,000 | 201 |
| Santander Customer Satisfaction | binary | AUC | 2016 | 5,115 | 76,000 | 370 |
| porto-seguro-safe-driver-prediction | binary | Gini | 2018 | 5,156 | 600,000 | 58 |
| IEEE Fraud Detection | binary | AUC | 2019 | 6,351 | 590,000 | 432 |
| Walmart Recruiting Trip Type Classification | multi-class | log-loss | 2016 | 1,043 | 650,000 | 7 |
| Otto Group Product Classification Challenge | multi-class | log-loss | 2015 | 3,507 | 62,000 | 94 |
Each AutoML was trained for 4 hours on the m5.24xlarge EC2 machine (96 CPU and 384 GB RAM). The AutoML predictions on test data were evaluated on the private leaderboard by Kaggle’s internal scoring system. Below we report the Percentile Rank on the private leaderboard. The better solutions have higher Percentile Rank values. The first place solution in the competition will get Percentile Rank = 1. The results from Auto-WEKA, Auto-Sklearn, TPOT, H2O, GCP-Tables, AutoGluon presented here are from the AutoGluon article.
| Dataset | Auto-WEKA | auto-sklearn | TPOT | H2O AutoML | GCP-Tables | AutoGluon | MLJAR |
|---|---|---|---|---|---|---|---|
| ieee-fraud | 0.119 | 0.349 | x | x | 0.119 | 0.322 | 0.172 |
| value | 0.114 | 0.319 | 0.325 | 0.377 | x | 0.415 | 0.445 |
| walmart | x | 0.39 | 0.379 | x | 0.398 | 0.384 | 0.423 |
| transaction | 0.131 | 0.329 | 0.326 | x | 0.404 | 0.406 | 0.463 |
| porto | 0.158 | 0.331 | 0.315 | 0.406 | 0.434 | 0.462 | 0.54 |
| allstate | 0.124 | 0.31 | 0.237 | 0.352 | 0.74 | 0.706 | 0.764 |
| mercedes | 0.16 | 0.444 | 0.547 | 0.363 | 0.658 | 0.169 | 0.879 |
| otto | 0.145 | 0.717 | 0.597 | 0.729 | 0.821 | 0.988 | 0.924 |
| satisfaction | 0.235 | 0.408 | 0.495 | 0.74 | 0.763 | 0.823 | 0.975 |
| bnp-paribas | 0.193 | 0.412 | 0.46 | 0.417 | 0.44 | 0.986 | 0.986 |
Summary
The AutoML frameworks are getting better every day. The constant improvement is not only in their performance. The next-generation of AutoML can provide insights and explanations about analyzed data, create new features, and generate documentation (with native Notebooks support). The AutoML solutions are multi-purpose. They are used by different groups of users: seasoned data scientists, citizen data scientists, and software engineers.
References
- (Auto-Weka) C. Thornton, et al., Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms, 2013 https://www.cs.ubc.ca/labs/beta/Projects/autoweka/papers/autoweka.pdf
- (Auto-Sklearn) M. Feurer, et al., Efficient and Robust Automated Machine Learning, 2015 https://proceedings.neurips.cc/paper/2015/file/11d0e6287202fced83f79975ec59a3a6-Paper.pdf
- (TPOT) R. S. Olson, et al., Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science. Proceedings of GECCO 2016
- (AutoGluon) N. Erickson, et al., AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data, 2020
- (H2O) https://docs.h2o.ai/h2o/latest-stable/h2o-docs/automl.html
- (MLJAR AutoML) https://github.com/mljar/mljar-supervised
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Authors


Related Articles
- Machine Learning for Lead Scoring
- MLJAR AutoML adds integration with Optuna
- How to save and load Xgboost in Python?
- How to use early stopping in Xgboost training?
- CatBoost with custom evaluation metric
- MLJAR Studio a new way to build data apps
- Read Google Sheets in Python with no-code MLJAR Studio
- How to authenticate Python to access Google Sheets with Service Account JSON credentials
- Python Virtual Environment Explained
- Share Jupyter Notebook as web app