How does AutoML work?
Quick answer: AutoML automates preprocessing, model selection, tuning, and evaluation. It helps you move from raw data to strong baseline models faster.
The AutoML stands for Automated Machine Learning. It builds a Machine Learning pipeline in an automated way. But how exactly it works? What is behind the scene? There are many proprietary AutoML systems, and we probably never get to know how they work. Luckily, the MLJAR AutoML is open-source. Its code is available at GitHub. In this article, we will look inside MLJAR AutoML to show how it works.
Steps of AutoML
The MLJAR AutoML training consists of steps that are executed in the sequence. Not all steps are always executed, it depends on AutoML working mode (it can be Explain, Perform, Compete) and data properties.
The AutoML steps:
-
adjust_validation - this step selects the validation strategy. The strategy depends on the time limit for AutoML training and dataset size. It can select validation with 75%/25% train/test split, 5-fold cross validation, or 10-fold cross validation.
-
simple_algorithms - in this step the very simple algorithms are trained:
Baseline,Decision TreeandLinear. All algorithms used in this step are very fast to train and quickly provide the basline for performance. -
default_algorithms - in this step are trained algorithms with their default hyperparameters values. For each algorithm exactly one model is trained (with default params). The algorithms which can be trained in this step:
LightGBM,Xgboost,CatBoost,Neural Network,Random Forest,Extra Trees,Nearest Neighbors. -
not_so_random - in this step are trained algorithms with hyperparameters randomly drawn from the defined set of values. In this step are trained the same algorithms as in the default_algorithms step.
-
mix_encoding - this step only applies if categorical features are present in the training dataset. By the default all categorical features are converted to integers. In this step, if there are categorical features with cardinality smaller than 25 then they are converted into binary representation with one-hot encoding. This step is applied to algorithms:
XgboostandLightGBM. The mixed encoding is used with exaclty one model from each algorithm that best performed in the previous steps. -
golden_features - in this step the Golden Features are searched. They are inserted to the training data and used to retrain the 3 best performing models from the previous steps.
-
kmeans_features - in this step the K-Means Features are created. They are added to the training data and used to retrain the 3 best performing models from the previous steps.
-
insert_random_feature - in this step the random feature is inserted into the training data and the best performing model is retrained with new dataset. This step is a part of the Feature Selection procedure. After the training, the features with lower importance than random features are selected to be dropped.
-
features_selection - in this step, the best performing models from the previous steps are retrained with selected features only. If no features were dropped, then this step is omitted.
-
hill_climbing - in this step, the best performing models from previous steps are selected and one randomly chosen hyperparameter is changed for each. There can be several
hill_climbingsteps. -
boost_on_errors - in this step, the best performing model from previous steps is selected and retrain on the data with sample weight created to emphasize the mistakes of previous model.
-
ensemble - in this step, the
Ensemblemodel is created using all models from previous steps. -
stack - in this step, staced models are trained. The stacked data contains original data and out-of-folds predictions of the best models (from previous steps).
-
ensemble_stacked - in this step, the
Ensemblemodel is created using all models from previous steps.
Modes of AutoML
The MLJAR AutoML has 3 built-in modes that defines sets of steps. There are following modes available:
Explain- this mode is perfect for initial data analysis. It produces full explanations for ML models. It uses 75%/25% train/test split.Perform- this mode was designed to train models to be used for production. It uses 5-fold cross validation. The best ML pipeline is contructed under the prediction time limit on single sample below0.5seconds. Thus, this mode is perfect for training ML pipelines which will be used behind REST API.Compete- constructs ML pipeline with the highest prediction's accuracy. The perfect mode for data competitions or use-cases where even0.1%improvement matters (for example in financial use cases). It adjust the validation strategy based on total time limit.
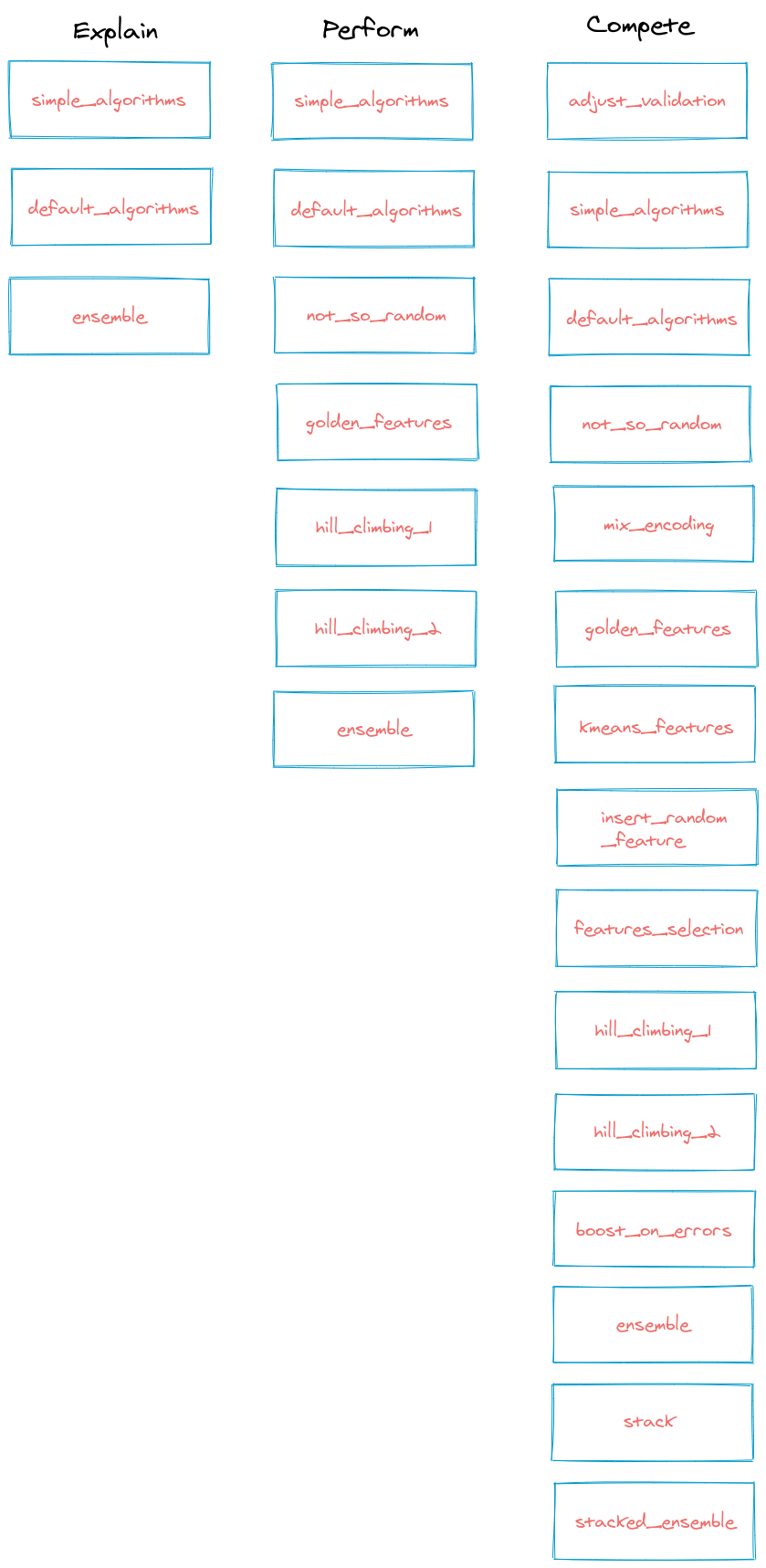
As you can see the Compete mode is using all steps. It needs a lot of train time to find the solution. Denepnding on the dataset it should use at least 1 hour for training. Good results should be obtained with 8-12 hours of the training.
Summary
The MLJAR AutoML is the next generation of Automated Machine Learning system. It provides not only hyperparameters tuning but also advanced feature engineering, explanations & interpretations of ML pipelines, and automatic documentation. I hope you will find very good ML models with MLJAR! :)
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- AutoML as easy as MLJar
- PostgreSQL and Machine Learning
- Tensorflow vs Scikit-learn
- Extract Rules from Decision Tree in 3 Ways with Scikit-Learn and Python
- AutoML in the Notebook
- Machine Learning for Lead Scoring
- MLJAR AutoML adds integration with Optuna
- How to save and load Xgboost in Python?
- How to use early stopping in Xgboost training?
- CatBoost with custom evaluation metric