PostgreSQL and Machine Learning
I will show you how to apply Machine Learning algorithms on data from the PostgreSQL database to get insights and predictions. I will use an Automated Machine Learning (AutoML) supervised. It is an open-source python package. Thanks to AutoML I will get quick access to many ML algorithms: Decision Tree, Logistic Regression, Random Forest, Xgboost, Neural Network. The AutoML will handle feature engineering as well. I will show you python code snippets that can be reused to integrate Machine Learning with PostgreSQL as a part of the ETL pipeline.
You can find all the code used in this post in the GitHub.
The marketing data
I will use Portugese Bank Marketing dataset (bank_cleaned.csv file). This dataset is about the marketing campaigns, which aim to promote financial products for existing customers of a Portuguese bank. The each contact to the client is described by:
columns = ["age", "job", "marital", "education", "default_payment", "balance", "housing", "loan", "day", "month", "duration", "campaign", "pdays", "previous", "poutcome" "response" # the target ]
The response is the taget column, which contains the information if customer subscribed to the financial product. The goal of the analysis will be to predict whether customer will select the subscription.
In this analysis I will split the dataset into:
- training data (
32,672samples), - testing data (
8,169samples).
All datasets are inserted into database, but for testing data the response is not inserted.
Setup PostgreSQL database in Docker
I will set-up the PostgreSQL database in the docker.
The Dockerfile with PostgreSQL:
FROM postgres:alpine
EXPOSE 5555
To build docker image and run container:
docker build -t mydb:latest .
docker run --name my_local_db -e POSTGRES_PASSWORD=1234 -e POSTGRES_DB=db -p 5555:5432 mydb:latest
Create table and insert the training data
For interacting with the database I will use python scripts and psycopg2 package. To initialize the database please use the init_db.py file. Let's dig into the code.
""" init_db.py file """ import numpy as np import pandas as pd import psycopg2 from io import StringIO from sklearn.model_selection import train_test_split from db import db_engine create_table_sql = """ CREATE TABLE IF NOT EXISTS marketing ( id serial PRIMARY KEY, age integer, job varchar(128), marital varchar(128), education varchar(128), default_payment varchar(128), balance integer, housing varchar(128), loan varchar(128), day integer, month varchar(128), duration real, campaign integer, pdays integer, previous integer, poutcome varchar(128), response varchar(128), predicted_response varchar(128) ) """ get_data_sql = """select * from marketing""" df = pd.read_csv("data/bank_cleaned.csv", index_col="id") df.drop("response_binary", axis=1, inplace=True) df["predicted_response"] = "" test_size= 0.20 # 20% for testing df_train, df_test = train_test_split(df, test_size=test_size, random_state=1234) df_train.to_csv("data/train.csv") df_test.to_csv("data/test.csv") df_test = df_test.copy() df_test["response"] = "" df = pd.concat([df_train, df_test]) try: conn = psycopg2.connect(db_engine()) cur = conn.cursor() print("Create marketing table") cur.execute(create_table_sql) conn.commit() print("Insert train and test data into table ...") buffer = StringIO() df.to_csv(buffer, index_label="id", header=False) buffer.seek(0) cur.copy_from(buffer, "marketing", sep=",") conn.commit() print("Insert finished.") cur.close() except Exception as e: print("Problems:", str(e))
The code is doing three things:
- Create the
marketingtable if it not exists. - Split the data into train and test sets (
80%/20%split). Datasets are saved to the disk. - Datasets are inserted into table in the database. The
responsevalues is removed from test samples.
The data is in the database. Let's log into PostgreSQL to check:
> psql -U postgres -d db --host=0.0.0.0 --port=5555
db=# select count(*) from marketing;
count
-------
40841
(1 row)
db=# select response, count(*) from marketing group by response;
response | count
----------+-------
no | 28952
| 8169
yes | 3720
(3 rows)
Let's train the Machine Learning models!
To integrate PostgreSQL with Machine Learning we will need:
- method to get training data -
get_train_data(), - method to get live data (for computing predictions) -
get_live_data(), - method to insert predictions into the database -
insert_predictions(predictions, ids), - method to get predictions (to compute the accuracy) -
get_predictions().
I've created db.py file to communicate with the database (with psychopg2):
""" db.py file """ """ Database API """ import json import numpy as np import pandas as pd import psycopg2 from io import StringIO def db_engine(): config = json.load(open("config.json")) host = config["connection"]["host"] port = config["connection"]["port"] user = config["connection"]["user"] # password should be hidden in production setting # do not store it in config.json password = config["connection"]["password"] db = config["connection"]["db"] return "user='{}' password='{}' host='{}' port='{}' dbname='{}'".format( user, password, host, port, db ) def sql_to_df(sql_query): try: conn = psycopg2.connect(db_engine()) cur = conn.cursor() cur.execute(sql_query) df = pd.DataFrame(cur.fetchall(), columns=[elt[0] for elt in cur.description]) cur.close() return df except Exception as e: print("Problems:", str(e)) return None def get_train_data(): config = json.load(open("config.json")) table = config["automl"]["table"] features = config["automl"]["features"] target = config["automl"]["target"] get_data_sql = f"select {','.join(features+[target])} from {table} where {target} != ''" df = sql_to_df(get_data_sql) if df is None: return None, None return df[features], df[target] def get_live_data(): config = json.load(open("config.json")) table = config["automl"]["table"] features = config["automl"]["features"] target = config["automl"]["target"] predicted = config["automl"]["predicted"] id_column = config["automl"]["id"] get_data_sql = f"select {','.join(features + [id_column])} from {table} where {target} = '' and {predicted} = ''" df = sql_to_df(get_data_sql) if df is None: return None, None return df[features], df[id_column] def get_predictions(): config = json.load(open("config.json")) table = config["automl"]["table"] target = config["automl"]["target"] predicted = config["automl"]["predicted"] id_column = config["automl"]["id"] get_data_sql = f"select {','.join([predicted] + [id_column])} from {table} where {target} = ''" df = sql_to_df(get_data_sql) if df is None: return None df.index = df[id_column] return df def insert_predictions(predictions, ids): config = json.load(open("config.json")) table = config["automl"]["table"] predicted = config["automl"]["predicted"] id_column = config["automl"]["id"] try: conn = psycopg2.connect(db_engine()) cur = conn.cursor() tuples = list(zip(predictions, ids)) sql_query = f"update {table} set {predicted} = %s where {id_column} = %s" cur.executemany(sql_query, tuples) conn.commit() except Exception as e: print("Problems:", str(e))
You can see that all information needed to connect and to get data is loaded from config.json file:
{
"connection": {
"host": "0.0.0.0",
"port": 5555,
"user": "postgres",
"password": "1234",
"db": "db"
},
"automl": {
"table": "marketing",
"features": [
"age",
"job",
"marital",
"education",
"default_payment",
"balance",
"housing",
"loan",
"day",
"month",
"duration",
"campaign",
"pdays",
"previous",
"poutcome"
],
"target": "response",
"predicted": "predicted_response",
"id": "id"
}
}
- This file contains connection details (
host,port,user,password,db). - Additionaly, it defines the data source for Machine Learning (
tableparameter). Thefeaturesdescribe the AutoML input,target- the AutoML output,predicted- the name of the column where predictions will be stored, andidis the index column. - You can resuse this file to define your own integration of PostgreSQL with AutoML.
- The password is in the config file just for example purposes. In production setting, it should be hidden (as environment variable).
Let's train AutoML
You might find it suprissing but there are only 5 lines of code in the train_automl.py file:
""" train_automl.py file """ from db import get_train_data from supervised import AutoML # get the training data X_train, y_train = get_train_data() # train AutoML automl = AutoML(results_path="Response_Classifier") automl.fit(X_train, y_train)
This code gets data for training from the database and fit() AutoML object. The result of the AutoML are saved in Response_Classifier directory. All models and preprocessing details are automatically saved to the hard drive. Additionally, the README.md Markdown reports are created for AutoML and each Machine Learning model. You can check them on GitHub, here are links for few examples:
| Best model | name | model_type | metric_type | metric_value | train_time | Link |
|---|---|---|---|---|---|---|
| 1_Baseline | Baseline | logloss | 0.354508 | 0.32 | Results link | |
| 2_DecisionTree | Decision Tree | logloss | 0.269144 | 15.8 | Results link | |
| 3_Linear | Linear | logloss | 0.237079 | 7.45 | Results link | |
| 4_Default_RandomForest | Random Forest | logloss | 0.230933 | 14.16 | Results link | |
| 5_Default_Xgboost | Xgboost | logloss | 0.203599 | 10.48 | Results link | |
| 6_Default_NeuralNetwork | Neural Network | logloss | 0.209968 | 27.67 | Results link | |
| the best | Ensemble | Ensemble | logloss | 0.199728 | 1.75 | Results link |
From the results you can see that the best model is an Ensemble (which is combination of Xgboost and Neural Network).
The Ensemble breaks the 0.2 logloss level, when any of single algorithms cannot.
Do you need Machine Learning at all?
There is a Baseline algorithm trained by AutoML. It returns the most frequent class as predictions. To check if you need Machine Learning at all, we can compare the best model performance with the Baseline:
% difference = (0.3545 - 0.1997) / 0.3545 * 100.0 = 43.67%
The best models is 43% better than Baseline. Yes, you should Machine Learning for solving this problem. (I would consider a difference smaller than 5%-10% as a sign to reconsider Machine Learning usage or a need to do a double-check of your data)
Automated Exploratory Data Analysis
The AutoML has a feature to compute Automated Explortatory Data Analysis (EDA). All plots and informations from the EDA are saved in Markdown report which can be checked in this link. (Do you see that all reports are stored in GitHub? so they can be easily shared)
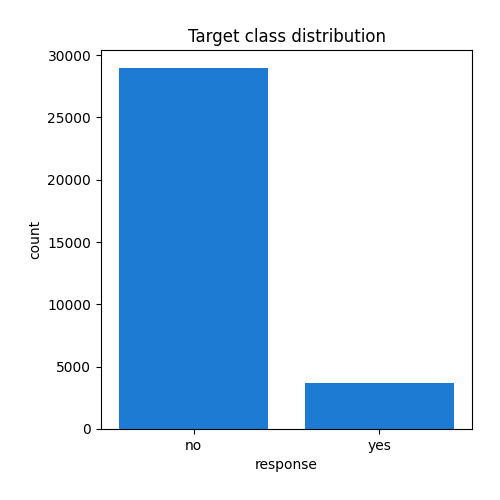
Example EDA for Target
Feature: target
Feature type: categorical
Missing: 0.0%
Unique: 2
Count:32672
Unique: 2
Top: no
Freq: 28952
Insights with Explainability
By the default the supervised produces explanations for models. Let me show you few examples which are produced with 5 lines of code (2 lines of imports)
Decision Tree visualization
Visualization of the Decision Tree algorithm made with dtreeviz package. The visualization is available in the Markdown report.

Coefficients of Linear model
You can inspect the Linear model coefficients to check which one are the most used. I will show here top-10 coefficients (based on their values). The full list of coefficients can be found in the Markdown report.
| feature | Learner_1 |
|---|---|
| month_mar | 1.65158 |
| poutcome_success | 1.60419 |
| month_sep | 1.1394 |
| duration | 1.07018 |
| month_oct | 1.01796 |
| month_dec | 0.611299 |
| job_retired | 0.510886 |
| job_student | 0.501499 |
| job_admin. | 0.223268 |
| education_tertiary | 0.219852 |
| ... | ... |
Feature Importance
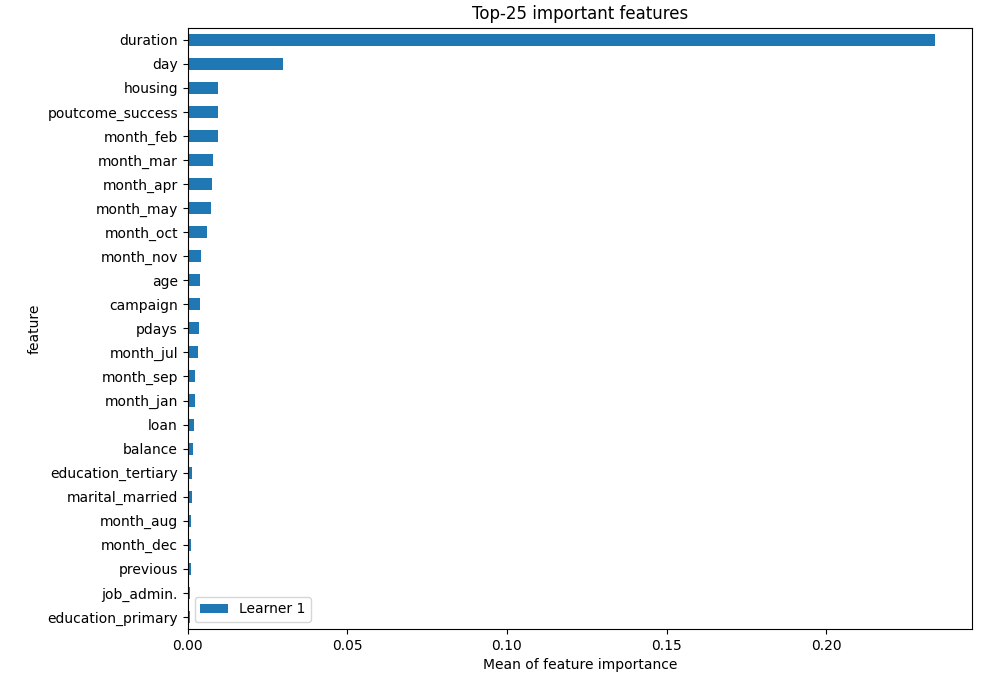
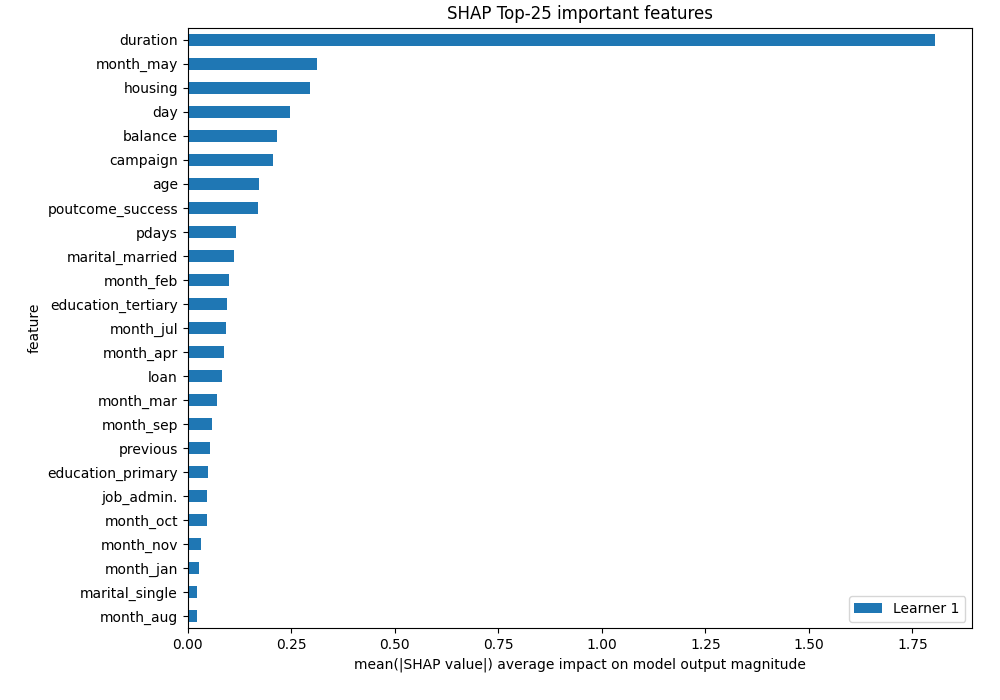
The Xgboost has the best performance as a single model. Let's check which features was the most important. The AutoML uses two methods to get feature importance:
- permutation-based feature importance,
- and SHAP-based feature importance.
Permutation-based importance
SHAP-based importance
SHAP Explanations - Dependence Plots
Additionally, the AutoML produces dependence plots with shap package:
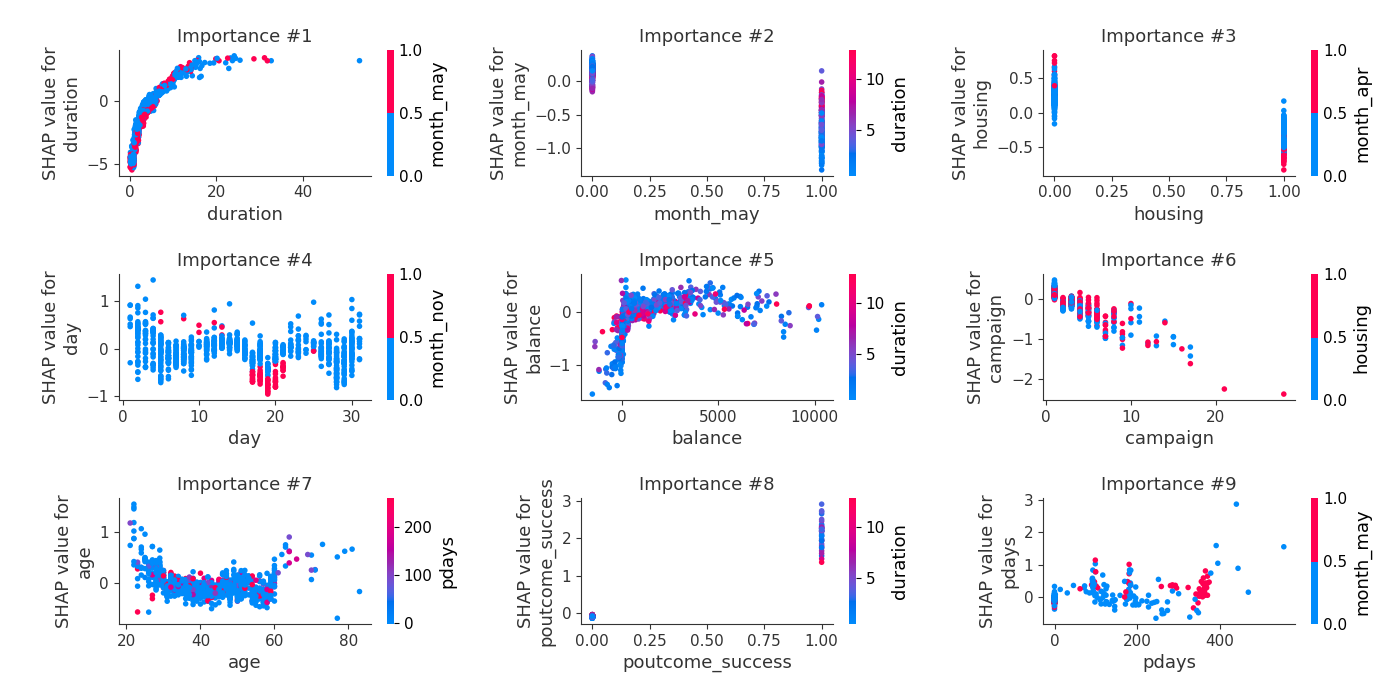
SHAP Explanations - Decision Plots
The decision plots for top-10 correct classification for response=yes:
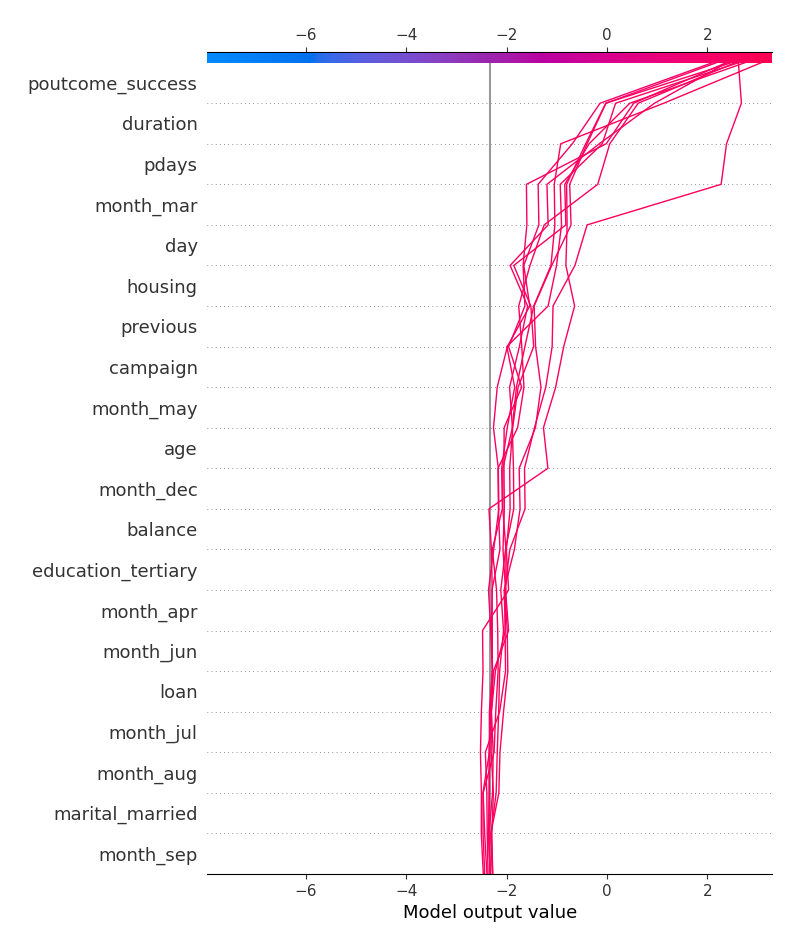
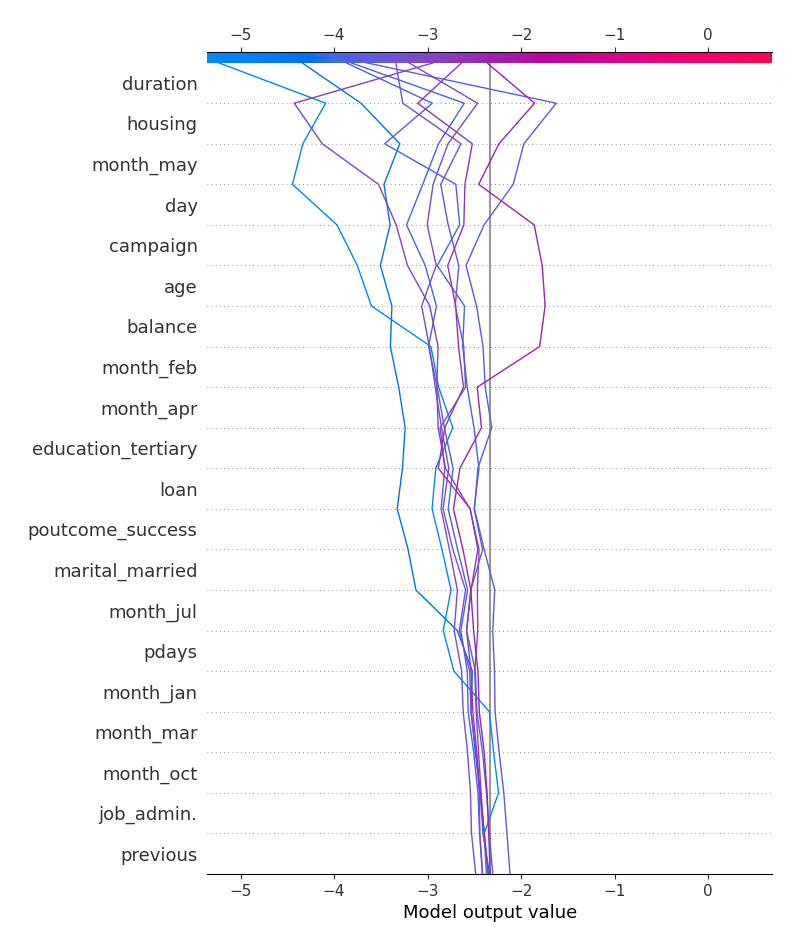
The decision plots for top-10 incorrect classification for response=yes:
Predict
OK, enough. You definetly see that supervised is an amazing ML package. Let's use our model to compute predictions and insert them into PostgreSQL:
""" predict.py file """ from db import get_live_data from db import insert_predictions from supervised import AutoML X_live, ids = get_live_data() if X_live is None or not X_live.shape[0]: print("No new data") else: print("Compute predictions") automl = AutoML(results_path="Response_Classifier") predictions = automl.predict(X_live) print("Insert prediction into DB") insert_predictions(predictions, ids)
The code for computing predictions work in three steps:
- Get live data - data without
reponse(our target) andpredicted_responsevalues. - Compute predictions from AutoML (ensemble of
XgboostandNeural Network). - Insert predictions into the database.
How does it look in the database:
db=# select * from marketing where predicted_response in ('yes', 'no') limit 10;
id | age | job | marital | education | default_payment | balance | housing | loan | day | month | duration | campaign | pdays | previous | poutcome | response | predicted_response
-------+-----+---------------+----------+-----------+-----------------+---------+---------+------+-----+-------+----------+----------+-------+----------+----------+----------+--------------------
44301 | 35 | management | married | tertiary | no | 775 | no | no | 27 | jul | 0.15 | 1 | -1 | 0 | unknown | | no
2940 | 41 | services | married | secondary | no | 890 | yes | no | 14 | may | 13.82 | 1 | -1 | 0 | unknown | | yes
43358 | 26 | student | married | tertiary | no | 8750 | no | no | 26 | mar | 1.63 | 2 | -1 | 0 | unknown | | no
6184 | 28 | management | single | tertiary | no | 939 | yes | no | 27 | may | 12.33 | 1 | -1 | 0 | unknown | | yes
1991 | 44 | unemployed | married | secondary | no | -407 | yes | no | 9 | may | 1.98 | 2 | -1 | 0 | unknown | | no
35422 | 31 | technician | single | secondary | no | 1626 | no | no | 7 | may | 5.93 | 2 | 286 | 3 | failure | | no
25082 | 33 | self-employed | divorced | tertiary | no | 454 | no | yes | 18 | nov | 2.23 | 1 | -1 | 0 | unknown | | no
21757 | 47 | management | married | tertiary | no | 600 | no | no | 19 | aug | 4.83 | 15 | -1 | 0 | unknown | | no
45162 | 29 | admin. | single | secondary | no | 464 | no | no | 9 | nov | 3.47 | 2 | 91 | 3 | success | | yes
30301 | 39 | technician | married | primary | no | 1846 | no | no | 5 | feb | 5.1 | 5 | -1 | 0 | unknown | | no
(10 rows)
Nice, isn't it? You can fill your database with information from the future!
Feedback and accuracy
OK, let's assume that some time have passed and the 'real' response value is known, so we can compute the accuracy of the model.
""" feedback.py file """ """ Compute accuracy of predictions """ import json import numpy as np import pandas as pd from db import get_predictions config = json.load(open("config.json")) target = config["automl"]["target"] predicted = config["automl"]["predicted"] id_column = config["automl"]["id"] test = pd.read_csv("data/test.csv", index_col=id_column) predictions = get_predictions() test[predicted] = predictions[predicted] accuracy = np.round(np.sum(test[predicted] == test[target]) / test.shape[0] * 100.0, 2) print(f"Accuracy: {accuracy}%")
This code has three steps:
- Get test data from the file with 'real'
responsevalues. - Get predictions from the database.
- Compute the accuracy of the predictions.
Running the feedback.py file will print-out the accuracy:
python feedback.py
Accuracy: 91.14%
The accuracy means that 91.14% of answers from our Machine Learning model were correct! Pretty nice! :)
Summary
- The python scripts for communication between PostgreSQL and Machine Learning were showed. The scripts can be extended and used as a part of ETL pipeline.
- The Machine Learning model was trained with Automated Machine Learning package:
supervised. - The described solution pulled data from PostgreSQL and keep it in the local memory. There are solutions for in-database Machine Learning, for example MADlib, which can train ML models in-database. From my experience, in-database offer of algorithms is limited (just basic ML models). Even for in-database algorithms the data needs to be unloaded somewhere, so it can be limited by database's machine capacity. And please just imagine how does debugging in-database ML models will look like ...
- All code scripts are available at GitHub.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Author

Related Articles
- Random Forest Feature Importance Computed in 3 Ways with Python
- How to visualize a single Decision Tree from the Random Forest in Scikit-Learn (Python)?
- How many trees in the Random Forest?
- Xgboost Feature Importance Computed in 3 Ways with Python
- AutoML as easy as MLJar
- Tensorflow vs Scikit-learn
- Extract Rules from Decision Tree in 3 Ways with Scikit-Learn and Python
- AutoML in the Notebook
- How does AutoML work?
- Machine Learning for Lead Scoring