Fairness in Automated Machine Learning
Starting from version 1.0.0 our open-source Automated Machine Learning Python package mljar-supervised is supporting fairness aware training of Machine Learning pipelines. Our AutoML can measure fairness and mitigate bias for provided sensitive features. We support three Machine Learning tasks: binary classification, multiclass classification and regression. We provide usage and implementation details in this article.
Fairness definition
Fairness in Machine Learning refers to the ethical consideration of ensuring equitable and unbiased treatment of individuals or groups when developing and deploying machine learning models. It emphasizes the need to avoid discrimination or disparate impact based on sensitive attributes such as race, gender, age, or ethnicity.
The goal of fairness in Machine Learning is to mitigate the potential biases that can emerge during the model's development, training, and decision-making processes. It seeks to ensure that the outcomes, predictions, or decisions made by machine learning algorithms do not unjustly favor or disadvantage certain individuals or groups.
Install or update MLJAR AutoML
Please install our Python package to use fairness-aware training:
pip install mljar-supervised
Please use the following command to update the package:
pip install -U mljar-supervised
You can also use conda:
conda install -c conda-forge mljar-supervised
Please make sure that you have MLJAR AutoML version above 1.0.0.
Dataset
Let's use the Adult dataset to illustrate how to use MLJAR AutoML for fair training. You can download this dataset from OpenML.org.
Each sample in the dataset corresponds to a person. It has such attributes as age, work class, education, race, sex, marital status, employment, and information about yearly capital gain. The Machine Learning task is to train a binary classifier that predicts if a person makes above 50,000$ per year.
Let's load the dataset:
from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_openml from supervised.automl import AutoML data = fetch_openml(data_id=1590, as_frame=True) y = (data.target == ">50K") * 1 X = data.data y = (data.target == ">50K") * 1 sensitive_features = X[["sex"]] X_train, X_test, y_train, y_test, S_train, S_test = train_test_split( X, y, sensitive_features, stratify=y, test_size=0.75, random_state=42 )
The sex will be used as a sensitive feature. It is worth to mention, that MLJAR AutoML can handle multiple sensitive features. Sensitive features might be continuous or categorical. In the case of a continuous sensitive feature, it will be converted to binary with equal-size categories.
Fair AutoML API
Let's create an AutoML object. There are new arguments in the AutoML constructor:
fairness_metric- metric which will be used to decide if the model is fair,fairness_threshold- threshold used in decision about model fairness,privileged_groups- privileged groups used in fairness metrics computation,underprivileged_groups- underprivileged groups used in fairness metrics computation.
All the above arguments can be left blank, and AutoML will automatically set the best values for them depending on your training data and sensitive features.
Fairness metrics
The fairness_metric and fairness_threshold depends on the Machine Learning task. For binary and multiclass classification, there are available metrics:
demographic_parity_difference,demographic_parity_ratio- default fairness metric for classification tasks,equalized_odds_difference,equalized_odds_ratio.
Fairness metrics for regression:
group_loss_difference,group_loss_ratio- default fairness metric.
The fairness_threshold is determined automatically based on fairness_metric. Default fairness_threshold values are:
- for
demographic_parity_differencethe metric value should be below0.1, - for
demographic_parity_ratiothe metric value should be above0.8, - for
equalized_odds_differencethe metric value should be below0.1, - for
equalized_odds_ratiothe metric value should be above0.8. - for
group_loss_ratiothe metric value should be above0.8.
For group_loss_difference, the default threshold value can't be set because it depends on the dataset. If the group_loss_difference metric is used and fairness_threshold is not specified manually, then an exception will be raised.
We treat the model as fair if the fairness_metric value is above fairness_threshold for all metrics with ratio in the name.
For fairness_metric with difference in the name, the model fairness value should be below the fairness_threshold to treat the model as fair.
Privileged and Underprivileged groups
When constructing the AutoML object, we can pass information about privileged_groups and underprivileged_groups. If we don't set them, the AutoML will automatically set them based on the fairness metric. We can set none, one, or two of these arguments.
The privileged_groups and underprivileged_groups should be passed as a list of dictionaries. Each dictionary should contain only one item, with key equal to the sensitive feature column name, and value equal to the group value.
In our example, we have one sensitive feature, sex (it is a column name), with values Female and Male. The arguments will be:
# ... privileged_groups=[{"sex": "Male"}], underprivileged_groups=[{"sex": "Female"}] # ...
Construct AutoML object for fair training
Let's construct the AutoML object.
automl = AutoML( algorithms=["Xgboost"], fairness_metric="demographic_parity_ratio", fairness_threshold=0.8, privileged_groups = [{"sex": "Male"}], underprivileged_groups = [{"sex": "Female"}], train_ensemble=False )
We used only the Xgboost algorithm, it is for simplicity. You can use fair training with all algorithms available in our AutoML, including Ensemble and Stacked Ensemble.
In the above example, we set all fair training-related arguments.
We need to provide sensitive_features argument when calling fit() method:
automl.fit(X_train, y_train, sensitive_features=S_train)
That's all. We can run our script. Below is the expected output:
AutoML directory: AutoML_23 The task is binary_classification with evaluation metric logloss AutoML will use algorithms: ['Xgboost'] AutoML steps: ['simple_algorithms', 'default_algorithms', 'unfairness_mitigation'] Skip simple_algorithms because no parameters were generated. * Step default_algorithms will try to check up to 1 model 1_Default_Xgboost logloss 0.302785 trained in 6.02 seconds * Step unfairness_mitigation will try to check up to 1 model 1_Default_Xgboost_SampleWeigthing logloss 0.314331 trained in 6.27 seconds * Step unfairness_mitigation_update_1 will try to check up to 1 model 1_Default_Xgboost_SampleWeigthing_Update_1 logloss 0.325471 trained in 6.03 seconds AutoML fit time: 23.53 seconds AutoML best model: 1_Default_Xgboost_SampleWeigthing_Update_1
Please notice that a new step, unfairness_mitigation is included. The AutoML created three models:
1_Default_Xgboost- Xgboost model with default hyperparameters,1_Default_Xgboost_SampleWeighting- Xgboost model with default hyperparameters and applied Sample Weighting algorithm for bias mitigation,1_Default_Xgboost_SampleWeighting_Update_1- Xgboost model with default hyperparameters with updated sample weights for better bias mitigation.
The Sample Weighting algorithm computes the sample weights to equally treat samples from each group. The later updates, models with Update in the name`, are trying to manipulate sample weights further to provide better fairness metric scores.
We report the performance metrics and fairness metrics in the AutoML leaderboard.

Additionally, there is a scatter plot showing the dependency between performance and fairness:
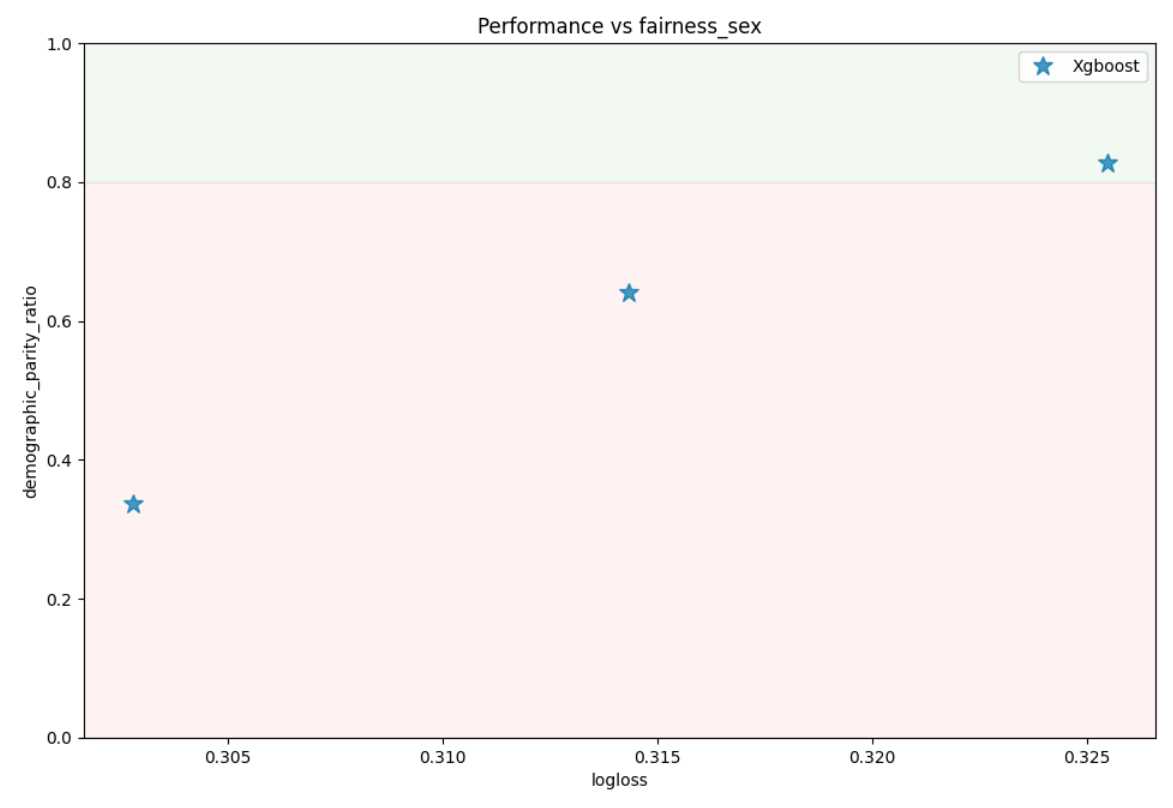
You observe that we have slight performance degradation when optimizing for fairness.
Fairness metrics without bias mitigation
You can click on the model in the leaderboard to check its metrics. Let's review the metrics without bias mitigation first.
We report the performance for each group in the sensitive feature.
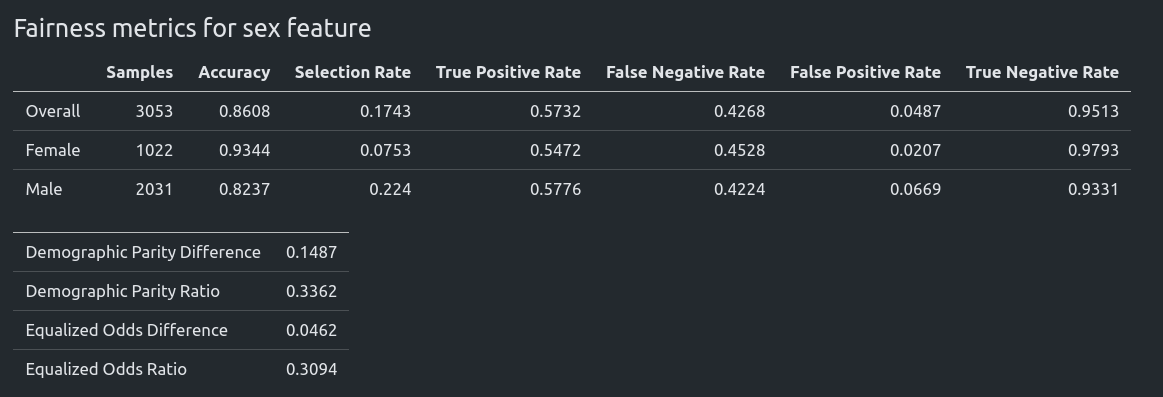
Please notice if there are multiple sensitive features, we report metrics for each feature.
Based on fairness_metric and fairness_threshold, we decide if the model is fair:

We include the Selection Rate for each group:
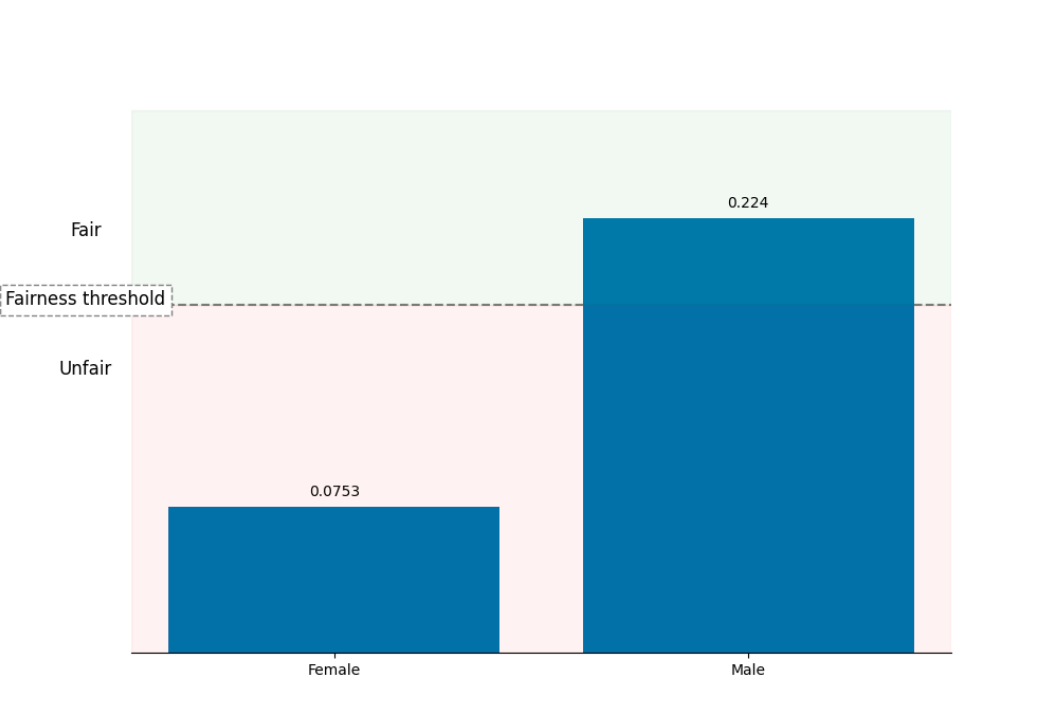
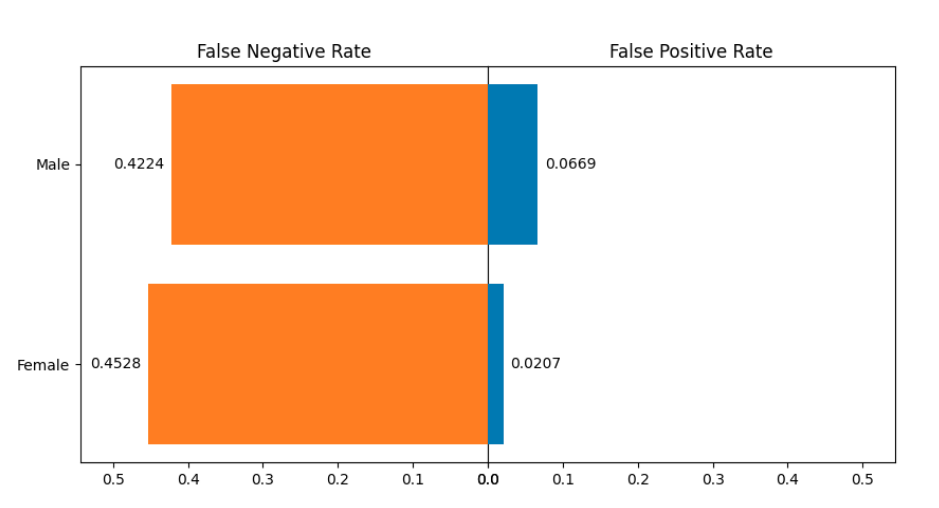
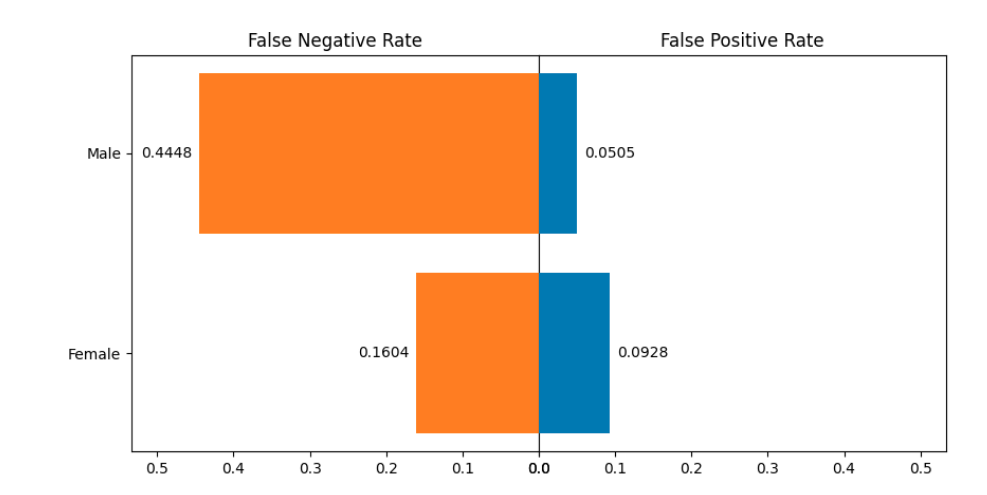
You can observe that the Selection Rate for Female is much lower than the Selection Rate for Male. It means that Male are more likely classified as earning more than 50k yearly. The False Rates plot:
Metrics after bias mitigation
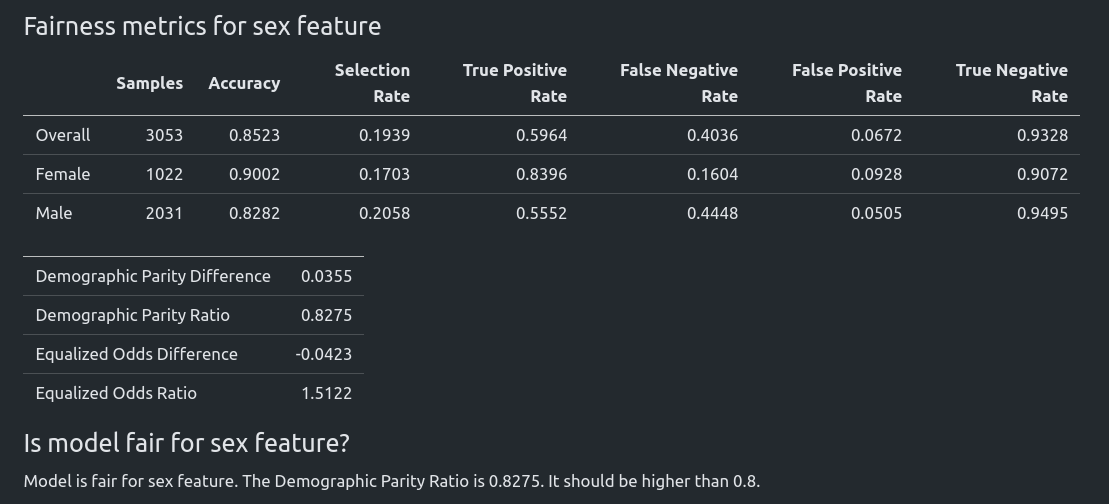
Let's check the model 1_Default_Xgboost_SampleWeighting_Update_1. It has Demographic Parity Ratio equal 0.8275 and is considered as a fair model.
The fairness metrics:
The Selection Rate plot. Please notice that after bias mitigation, the Selection Rate for Female and Male are at a similar level.
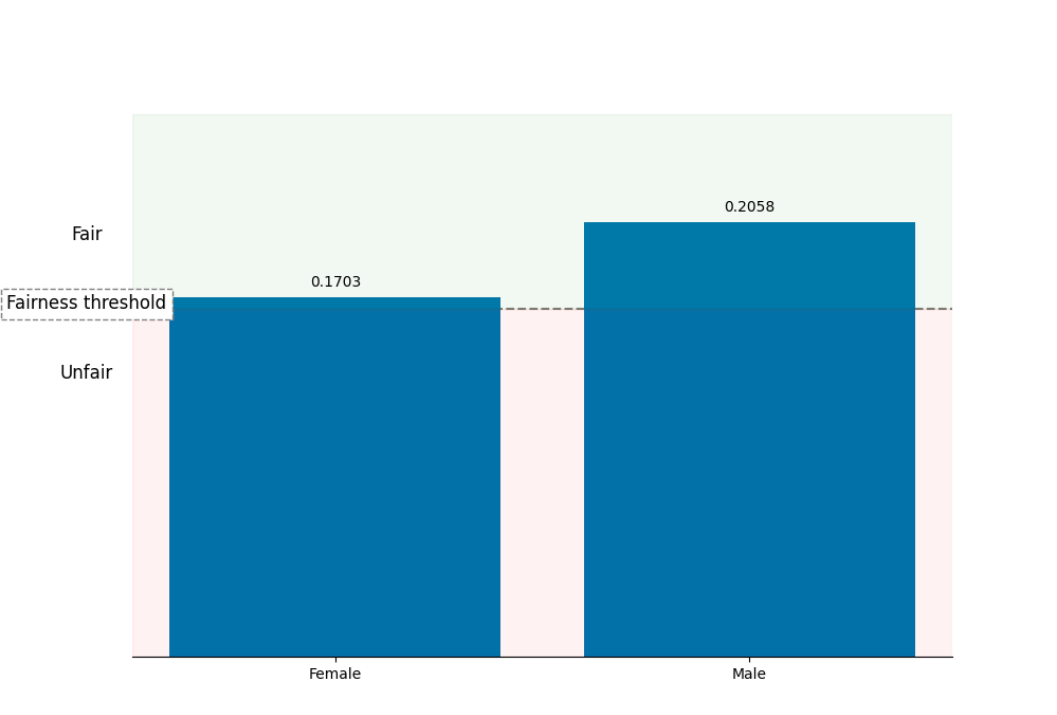
In the above plot, selection rates for both groups are above the fairness threshold.
Summary
We introduced support for fairness-aware training in the MLJAR AutoML. Our package is open-source with an MIT license. The GitHub repository is available at github.com/mljar/mljar-supervised.
We support fairness-aware training for binary and multiclass classification and regression tasks on tabular data. When sensitive features are passed in the fit() method, then fairness metrics and plots are included in the AutoML report. Fairness aware training is available for all algorithms, including Ensemble and Stacked Ensemble. What is more, it works with all validation strategies.
AI Data Analyst on Your Computer
Use MLJAR Studio to explore data, find insights, and create reports with AI. Everything runs locally, so your data stays with you.
About the Authors


Related Articles
- Convert Jupyter Notebook to Python script in 3 ways
- 3 ways to get Pandas DataFrame row count
- 9 ways to set colors in Matplotlib
- Jupyter Notebook in 4 flavors
- Python Dashboard for 15,963 Data Analyst job listings
- 3 ways to access credentials in Jupyter Notebook
- How to create Dashboard in Python from PostgreSQL
- How to create Invoice Generator in Python
- ChatGPT can talk with all my Python notebooks
- Create Retrieval-Augmented Generation using OpenAI API