The 2 ways to convert Jupyter Notebook Presentation to PDF slides
Jupyter Notebook can be used to create data-rich presentations. They can be presented as interactive slideshow thanks to Reveal.js library. What if you would like to export it to PDF slides? I will show you two approaches that you can use to export Jupyter Notebook presentation into PDF slides.
1. Print to PDF
This simplest approach is to use web browser functionality to print presentation to PDF file. However, we need to do one trick. In the URL address of our presentation you need to add ?print-pdf at the end.
For example, you are serving the slides locally with command:
jupyter nbconvert --to slides --post serve presentation.ipynb
You can check the presentation in the web browser at address:
- slides
http://127.0.0.1:8000/presentation.slides.html - printable slides
http://127.0.0.1:8000/presentation.slides.html?print-pdf.
There can be added #/ at the end: http://127.0.0.1:8000/presentation.slides.html?print-pdf#/.
Please open print dialog (Ctrl+P) and select Save as PDF:
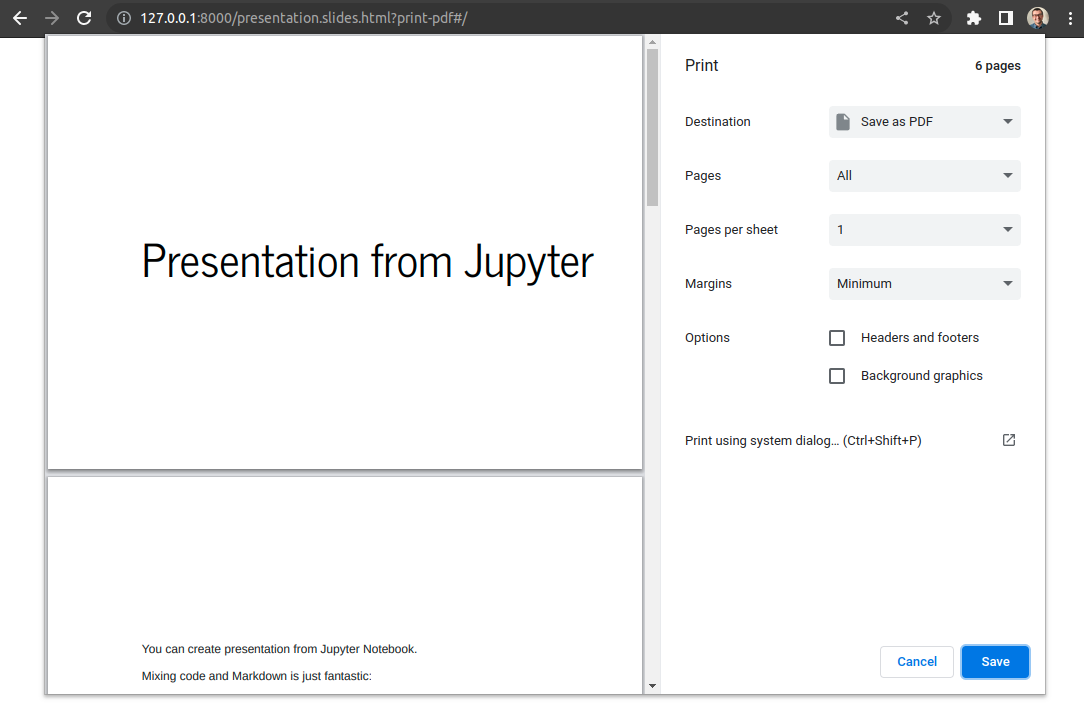
2. Convert HTML presentation to PDF with pyppeteer
What if you would like to convert Jupyter Notebook to PDF slides automatically? The next approach is to use pyppeteer. It is a headless chrome automation library. We will need to write small script that will accept HTML slides as input and produce PDF slides as an output.
Please install pyppeteer:
pip install pyppeteer
Create HTML slides from your Jupyter Notebook:
jupyter nbconvert --to slides presentation.slides.ipynb
There will be HTML file presentation.slides.html created.
Our Python script that produces PDF slides from HTML file:
import asyncio import os import tempfile from subprocess import PIPE, Popen from pyppeteer import launch import concurrent.futures async def html_to_pdf(html_file, pdf_file, pyppeteer_args=None): """Convert a HTML file to a PDF""" browser = await launch( handleSIGINT=False, handleSIGTERM=False, handleSIGHUP=False, headless=True, args=["--no-sandbox"], ) page = await browser.newPage() await page.setViewport(dict(width=994, height=768)) await page.emulateMedia("screen") await page.goto(f"file://{html_file}", {"waitUntil": ["networkidle2"]}) page_margins = { "left": "20px", "right": "20px", "top": "30px", "bottom": "30px", } dimensions = await page.evaluate( """() => { return { width: document.body.scrollWidth, height: document.body.scrollHeight, offsetWidth: document.body.offsetWidth, offsetHeight: document.body.offsetHeight, deviceScaleFactor: window.devicePixelRatio, } }""" ) width = dimensions["width"] height = dimensions["height"] await page.pdf( { "path": pdf_file, "format": "A4", "printBackground": True, "margin": page_margins, } ) await browser.close() if __name__ == "__main__": html_input_file = "/you/need/full/path/here/presentation.slides.html?print-pdf" pdf_output_file = "slides.pdf" pool = concurrent.futures.ThreadPoolExecutor() pool.submit( asyncio.run, html_to_pdf( html_input_file, pdf_output_file ), ).result()
Please note that you need to provide the full path to the HTML file (html_input_file variable). It will be opened in a headless web browser. The output PDF file is saved to pdf_output_file. Below is an example output:
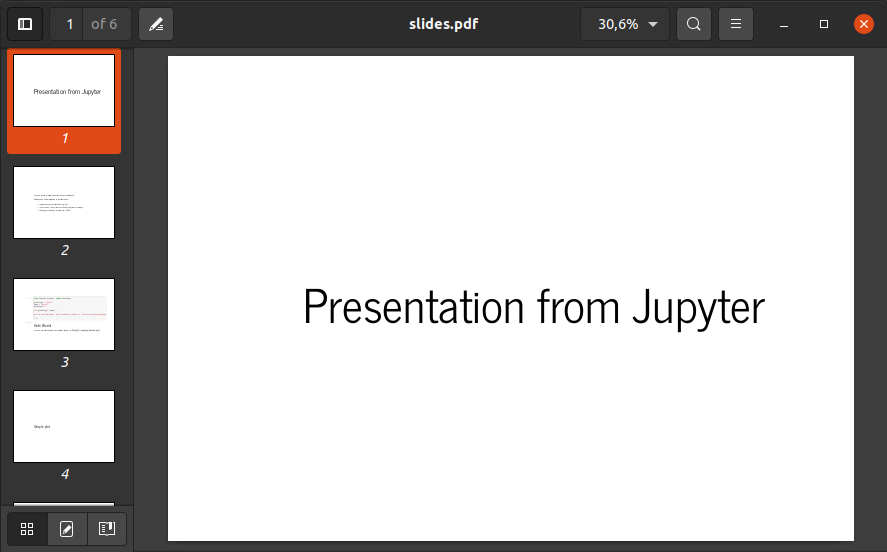
If you would like to apply styling, here is a longer version of the script.
Summary
Jupyter Notebook presentation is a great way to show data-rich results. Sometimes, you need to export slides to PDF (Portable Document Format). You can do this manually or automatically with simple Python script. In both approaches, please remember about adding ?print-pdf - it does the trick of converting Reveal.js slides into printable version.
We are working on a framework for sharing Jupyter Notebook with non-technical users. It is called Mercury. It can be used to create parameterized Jupyter Notebook presentations. Yes, presentations with widgets and slides that are recomputed during the slideshow!
Run AI for Machine Learning — Fully Local
MLJAR Studio is a private AI Python notebook for data analysis and machine learning. Generate code with AI, run experiments locally, and keep full control over your workflow.
About the Authors


Related Articles
- Create Presentation from Jupyter Notebook
- Create Parameterized Presentation in Jupyter Notebook
- The 3 ways to hide code in Jupyter Notebook Presentation
- Convert Jupyter Notebook to spaCy NLP web application
- The 4 ways to run Jupyter Notebook in command line
- The 3 ways to share password protected Jupyter Notebook
- The 3 ways to change figure size in Matplotlib
- The 5 ways to publish Jupyter Notebook Presentation
- The 2 ways to save and load scikit-learn model
- Complete list of 594 PyTZ timezones