The 2 ways to save and load scikit-learn model
After training of Machine Learning model, you need to save it for future use. In this article, I will show you 2 ways to save and load scikit-learn models. One method is using pickle package, it is fast but the model can take more storage than in the second approach. The alternative is to use joblib package, which can save some space on disk but is slower than the pickle.
We will first show you how to save and load scikit-learn models with pickle and joblib. Then we will measure the time needed by each package to save and load the same model. Additionally, we will check the storage needed to save the model in the disk for both libraries.
1. Save and load the scikit-learn model with pickle
The pickle library is a standard Python package - you don't need to install anything additional. It can be used to save and load any Python object to the disk.
Here is a Python snippet that shows how to save and load the scikit-learn model:
import pickle filename = "my_model.pickle" # save model pickle.dump(model, open(filename, "wb")) # load model loaded_model = pickle.load(open(filename, "rb"))
The full code example is below. The outline:
- train Random Forest model,
- save model to disk,
- load model from disk,
- compute predictions with loaded model.
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier # library for save and load scikit-learn models import pickle # load example data from sklearn X, y = load_iris(return_X_y=True) # create Random Forest Classifier rf = RandomForestClassifier() # fit model with all data - it is just example! rf.fit(X, y) # file name, I'm using *.pickle as a file extension filename = "random_forest.pickle" # save model pickle.dump(rf, open(filename, "wb")) # load model loaded_model = pickle.load(open(filename, "rb")) # you can use loaded model to compute predictions y_predicted = loaded_model.predict(X)
2. Save and load the scikit-load model with joblib
The joblib package needs to be installed additionally. It can be easily added to the Python environment with the below command:
pip install joblib
Below is an example Python code that shows how to save and load the scikit-learn model with joblib:
import joblib filename = "my_model.joblib" # save model joblib.dump(rf, filename) # load model loaded_model = joblib.load(filename)
The complete example code with joblib:
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier # library for save and load scikit-learn models import joblib # load example data from sklearn X, y = load_iris(return_X_y=True) # create Random Forest Classifier rf = RandomForestClassifier() # fit model with all data - it is just example! rf.fit(X, y) # file name, I'm using *.joblib as a file extension filename = "random_forest.joblib" # save model joblib.dump(rf, filename) # load model loaded_model = joblib.load(filename) # you can use loaded model to compute predictions y_predicted = loaded_model.predict(X)
In joblib you can pass the file name in the dump() or load() functions. In pickle we need to pass the file handle.
Compare the performance of pickle vs. joblib
First, let's compare the time needed to save and load the scikit-learn model. I'm using timeit magic command from Jupyter Notebook that runs code several times and measures the mean time needed to execute the function. In both cases, I'm saving and loading the same model for pickle and joblib.
filename = 'random_forest.pickle' # save with pickle %timeit -n 100 pickle.dump(rf, open(filename, 'wb')) >> 2.73 ms ± 82.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) # load with pickle %timeit -n 100 loaded_model = pickle.load(open(filename, 'rb')) >> 2.31 ms ± 144 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) filename = "random_forest.joblib" # save with joblib %timeit -n 100 joblib.dump(rf, filename) >> 35.7 ms ± 317 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) # load with joblib %timeit -n 100 loaded_model = joblib.load(filename) >> 26.7 ms ± 178 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Here is a screenshot from my notebook:
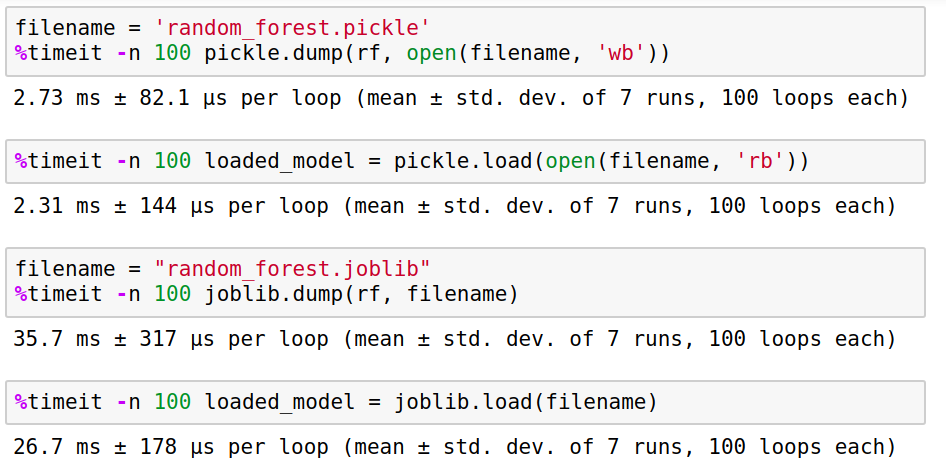
The pickle package is over 10 times faster than joblib for saving and loading models. It is a huge difference, especially if you are building an online service with Machine Learning models used for inference - the speed of response is crucial, and even milliseconds can make a difference.
Let's compare the file size. The file created with pickle has 165.3 KB. The file created with joblib has 170.4 KB. It was the same scikit-learn model. The pickle is faster (for saving and loading) and produces smaller files.
However, the joblib package has argument compress in the dump() function. It controls the level of file compression. It can be controlled with integer, boolean or touple (please check docs for more details). Herein, we will use an integer value from 0 to 9, where a higher number means more compression. Let's check the final file size for different levels of compression.
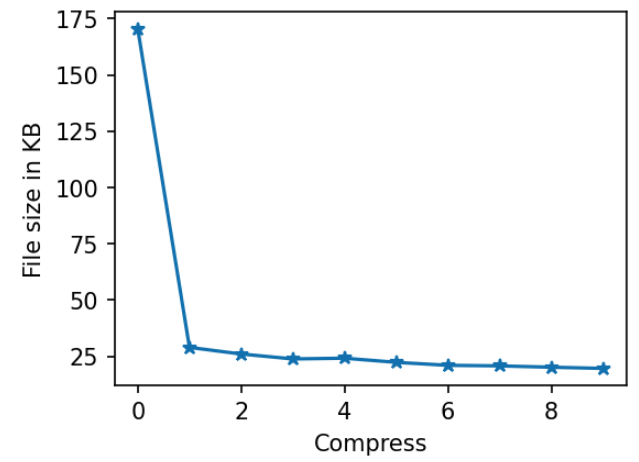
For the highest compression level, we get the file size 19.6 KB - it is over 8.6 smaller size than with no compression.
Let's check how saving time depends on compression level:
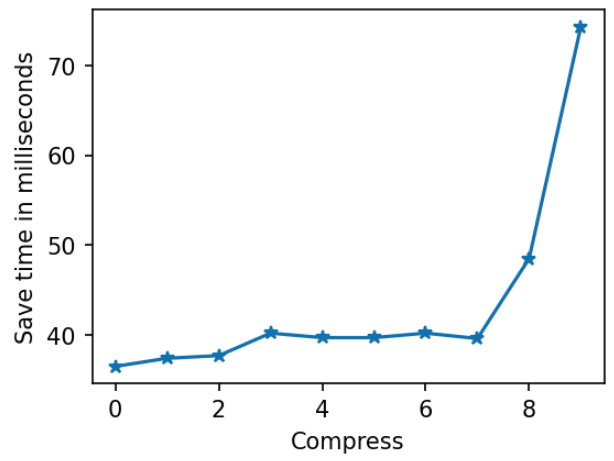
As expected, the larger the compression level, the more time is needed to save the model. Surprisingly, the load time is almost constant:
In joblib documentation, there is a note that compress=3 is often a good compromise between compression size and writing speed.
Security
There is a note in the pickle documentation that it can be insecure. It is shouldn't be used to load files from untrusted sources, because it can execute malicious code. For example, if you are building online Machine Learning service that accepts uploaded models, then you should use joblib. If you are bulding a Machine Learning system that will use only scikit-learn models produced by your system, then pickle will be a good choice.
Summary
There are two packages, pickle and joblib that can be used to save and load scikit-learn models. They have very similar APIs. The pickle package is faster in saving and loading models. The joblib can produce smaller file sizes thanks to compression. Additionally, scikit-learn models can be saved to PMML or ONNX formats, but additional packages are needed: sklearn-onnx and sklearn2pmml.
Explore next
Continue with practical guides, tutorials, and product workflows for Python, AutoML, and local AI data analysis.
- AI Data Analyst
Analyze local data with conversational AI support and notebook-based, reproducible Python workflows.
- AutoLab Experiments
Run autonomous ML experiments, track iterations, and inspect results in transparent notebook outputs.
- MLJAR AutoML
Learn how to train, compare, and explain tabular machine learning models with open-source automation.
- Machine learning tutorials
Step-by-step guides for beginners and practitioners working with Python, AutoML, and data workflows.
Run AI for Machine Learning — Fully Local
MLJAR Studio is a private AI Python notebook for data analysis and machine learning. Generate code with AI, run experiments locally, and keep full control over your workflow.
About the Authors


Related Articles
- The 4 ways to run Jupyter Notebook in command line
- The 2 ways to convert Jupyter Notebook Presentation to PDF slides
- The 3 ways to share password protected Jupyter Notebook
- The 3 ways to change figure size in Matplotlib
- The 5 ways to publish Jupyter Notebook Presentation
- Complete list of 594 PyTZ timezones
- Save a Plot to a File in Matplotlib (using 14 formats)
- Convert Jupyter Notebook to Python script in 3 ways
- 3 ways to get Pandas DataFrame row count
- 9 ways to set colors in Matplotlib