Machine Learning Algorithm Comparison
Did you know that there are over 200 machine learning algorithms available? With such a vast array of options, choosing the right one for your project can be challenging. This article aims to simplify this process by comparing several popular algorithms across various OpenML datasets. We’ll evaluate their performance on binary-classification, multi-class classification, and regression tasks to identify which algorithms excel in different scenarios.
As is often said in the industry, "There is no silver bullet for machine learning problems. Success in machine learning usually requires a combination of good data, domain expertise, and iterative experimentation." This underscores the importance of selecting the right algorithms and understanding their strengths and limitations. Our goal is to provide clear insights into how each algorithm performs, helping you make more informed choices.
Datasets
The study utilizes 42 OpenML datasets to ensure a comprehensive evaluation:
- 19 datasets for binary classification tasks
- 7 datasets for multi-class classification tasks
- 16 datasets for regression tasks
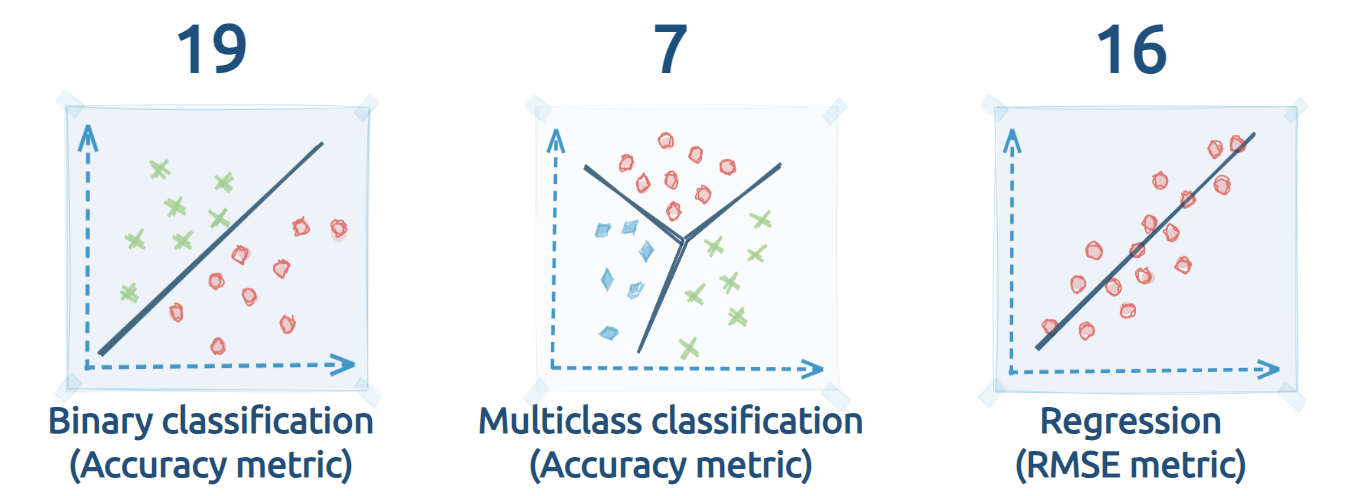
Each dataset was selected to provide a broad representation of real-world data challenges and to ensure a robust comparison across different scenarios.
Evaluated Algorithms
- Baseline: Serving as a simple reference point for comparison, this approach often involves basic heuristics or straightforward statistical methods to establish a performance baseline.
- CatBoost: A gradient boosting algorithm developed by Yandex, designed to efficiently handle categorical features and reduce overfitting through its use of ordered boosting. Known for its robustness and effectiveness in various types of data.
- Decision Tree: A fundamental algorithm that splits data into subsets based on feature values, creating a tree-like model of decisions. It's valued for its interpretability and ease of use in both classification and regression tasks.
- Extra Trees: This technique builds multiple decision trees using random subsets of data and features, then averages their predictions. It enhances accuracy and robustness by reducing variance compared to individual decision trees.
- LightGBM: A gradient boosting framework by Microsoft, optimized for speed and efficiency. It uses a histogram-based method for faster training and can handle large datasets with high-dimensional features effectively.
- Neural Network: A model inspired by the human brain, consisting of layers of interconnected nodes (neurons) that learn complex patterns. Suitable for tasks where deep learning capabilities can extract intricate features from data.
- Random Forest: An ensemble learning method that constructs multiple decision trees and combines their outputs to improve performance and generalization. It reduces overfitting by averaging predictions from many trees.
- Xgboost: An advanced gradient boosting framework known for its high performance and scalability. It incorporates regularization techniques to prevent overfitting and is widely used in machine learning competitions.
Training and Validation
- AutoML Configuration: The algorithms were trained using the mljar-supervised AutoML tool with advanced feature engineering turned off and without ensembling.
- Cross-Validation: Each model was evaluated using 5-fold cross-validation, which includes shuffling and stratification for classification tasks to ensure a robust assessment.
- Hyperparameter Tuning: Different hyperparameters were tested for each algorithm to optimize their performance and compare their effectiveness.
automl = AutoML( mode="Compete", total_time_limit=600, results_path=result_path, algorithms=[algorithm], train_ensemble=False, golden_features=False, features_selection=False, stack_models=False, kmeans_features=False, explain_level=0, boost_on_errors=False, eval_metric=eval_metric, validation_strategy={ "validation_type": "kfold", "k_folds": 5, "shuffle": True, "stratify": True, "random_seed": 123 }, start_random_models=10, hill_climbing_steps=3, top_models_to_improve=3, random_state=1234)
Evaluation Metrics
Binary and Multi-Class Classification
- Accuracy: The primary metric used for evaluating classification tasks. Accuracy measures the proportion of correctly classified instances out of the total instances. It is a straightforward and widely-used metric to assess model performance in classification tasks.
Regression
- Root Mean Square Error (RMSE): The metric used to evaluate regression tasks. RMSE measures the square root of the average squared differences between predicted and actual values. It provides an indication of the model's prediction accuracy, with lower values indicating better performance.
Results
Binary Classification Results
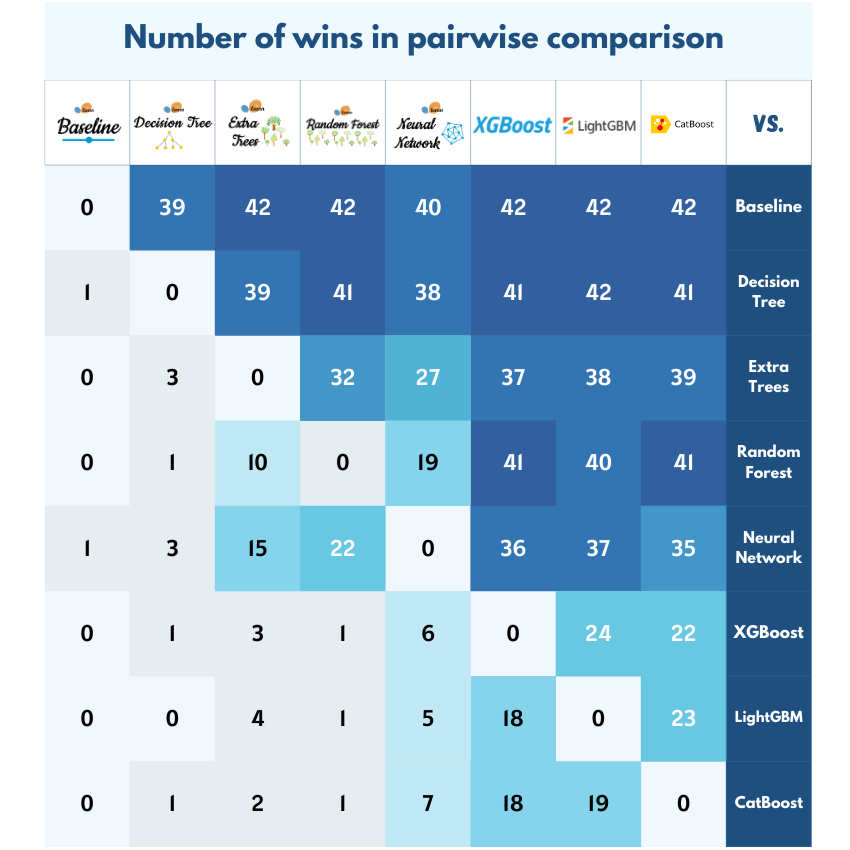
For the binary classification tasks, we evaluated the number of wins each algorithm achieved across the 19 datasets:
- Baseline: No wins, acting as a reference for comparison but not performing well against the more advanced algorithms.
- CatBoost: Dominated with 114 wins, showcasing its strength in handling binary classification tasks.
- Decision Tree: Recorded 20 wins, offering some success but generally outperformed by more sophisticated models.
- Extra Trees: Achieved 52 wins, benefiting from its ensemble approach to boost accuracy.
- Random Forest: Secured 67 wins, leveraging its ensemble technique to provide solid performance.
- LightGBM: Not far behind CatBoost, LightGBM secured 108 wins, demonstrating its effectiveness on large datasets.
- Neural Network: Managed 53 wins, showing its ability to capture complex patterns but slightly trailing behind other models.
- Xgboost: Matched LightGBM with 108 wins, reaffirming its position as a top contender in binary classification tasks.
Multi-Class Classification Results
For the multi-class classification tasks across 7 datasets, the algorithms performed as follows:
- Baseline: No wins, again serving as a basic benchmark for comparison.
- CatBoost: Secured 39 wins, leading the pack in handling multi-class classification problems.
- Decision Tree: Recorded 7 wins, outperforming the baseline but lagging behind the advanced models.
- Extra Trees: Achieved 18 wins, using its ensemble method to improve accuracy.
- Random Forest: Secured 17 wins, performing reliably across multi-class tasks.
- LightGBM: Excelled with 42 wins, demonstrating its superiority in multi-class classification tasks.
- Neural Network: Recorded 35 wins, performing strongly but falling short of LightGBM and CatBoost.
- Xgboost: Achieved 37 wins, showcasing its efficiency in multi-class classification, but slightly behind LightGBM and CatBoost.
Regression Results
In regression tasks, performance was evaluated using Root Mean Square Error (RMSE) across the 16 datasets:
- Baseline: Managed 2 wins, acting as a basic reference but generally outperformed by other algorithms.
- CatBoost: Achieved 90 wins, demonstrating its capacity for minimizing prediction error in regression tasks.
- Decision Tree: Recorded 21 wins, offering some success but with limitations in performance compared to ensemble methods.
- Extra Trees: Secured 45 wins, benefiting from the ensemble approach to reduce variance and error.
- Random Forest: Achieved 56 wins, providing robust performance in regression problems.
- LightGBM: Dominated with 92 wins, showcasing its ability to efficiently handle large-scale regression tasks.
- Neural Network: Managed 54 wins, performing well but not surpassing the ensemble-based models.
- Xgboost: Secured 88 wins, continuing to perform effectively in regression tasks, though just short of LightGBM.
Conclusion
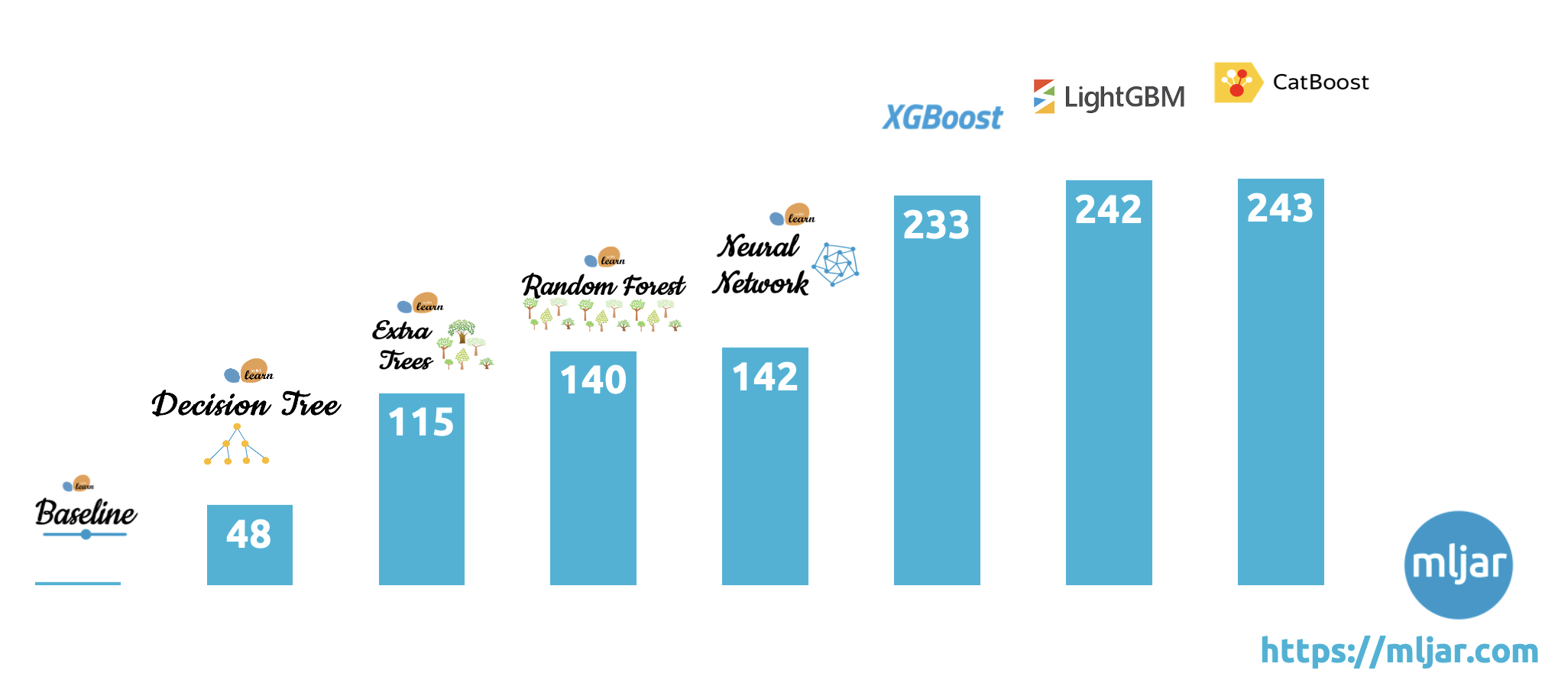
In this comparison of machine learning algorithms, CatBoost emerged as the top performer, with an impressive total of 243 wins across all tasks: 114 in binary classification, 39 in multi-class classification, and 90 in regression. This highlights CatBoost's strong capability across a variety of machine learning problems, particularly in handling categorical data and delivering high accuracy.
LightGBM closely followed with a total of 242 wins (108 binary classification, 42 multi-class classification, and 92 regression). It demonstrated exceptional performance, especially in multi-class classification and regression tasks, where its speed and scalability provided a significant edge.
Xgboost also proved to be highly competitive, securing 233 wins overall, with 108 in binary classification, 37 in multi-class classification, and 88 in regression. Its robust gradient boosting approach continues to make it a popular choice in a wide range of applications.
In summary, CatBoost stands out as the most effective algorithm across different types of machine learning tasks, with LightGBM and Xgboost close behind, offering powerful alternatives depending on the dataset and task complexity. These results highlight the importance of choosing the right algorithm for the specific problem at hand.
Explore next
Continue with practical guides, tutorials, and product workflows for Python, AutoML, and local AI data analysis.
- AI Data Analyst
Analyze local data with conversational AI support and notebook-based, reproducible Python workflows.
- AutoLab Experiments
Run autonomous ML experiments, track iterations, and inspect results in transparent notebook outputs.
- MLJAR AutoML
Learn how to train, compare, and explain tabular machine learning models with open-source automation.
- Machine learning tutorials
Step-by-step guides for beginners and practitioners working with Python, AutoML, and data workflows.
Run AI for Machine Learning — Fully Local
MLJAR Studio is a private AI Python notebook for data analysis and machine learning. Generate code with AI, run experiments locally, and keep full control over your workflow.
Related Articles
- How to create Dashboard in Python from PostgreSQL
- How to create Invoice Generator in Python
- ChatGPT can talk with all my Python notebooks
- Create Retrieval-Augmented Generation using OpenAI API
- Transfer data from Postgresql to Google Sheets
- TabNet vs XGBoost
- 4 Effective Ways to Visualize LightGBM Trees
- 4 Effective Ways to Visualize Random Forest
- 4 Effective Ways to Visualize XGBoost Trees
- Is weather correlated with cryptocurrency price?