AutoML Cyber Security Use Case
How AutoML Can Help
In this use case, we concentrate on a dataset intended for phishing website identification and classification. The PhishingWebsites dataset consists of multiple records of websites classified as "legitimate" or "phishing." Every record contains different attributes that could suggest whether a website is a phishing attempt, such as the length of the URL, whether HTTPS is present, the age of the domain, and other relevant information. The structure of the dataset offers a thorough understanding of the traits that set authentic websites apart from fraudulent ones, which is essential for creating reliable phishing detection models. This cyber security use case can greatly improve the process of phishing website detection through using MLJAR AutoML. The automated machine learning capabilities of MLJAR streamline the development of predictive models by automating the steps involved in data preprocessing, feature selection, model training, and hyperparameter tuning.
Business Value
30%
Faster
Up to 30% less time can be spent responding to incidents when using MLJAR AutoML automation. Quicker detection and reaction to security events lessen the possibility of harm and lessen the effect on company operations and reputation.
30%
Cost Efficiency
Implementing MLJAR AutoML can lower the costs associated with manual model development and maintenance by up to 30%. This cost savings comes from reduced need for specialized data science resources and the efficient automation of repetitive tasks.
40%
More Efficient
When compared to conventional techniques, MLJAR AutoML can expedite threat detection and response times by up to 40%. Security teams can detect and neutralize any threats faster because to this increased speed, which shortens the window of opportunity for attackers.
25%
False Positive Reduction
MLJAR AutoML can cut false positives by about 25% by optimizing model accuracy. This increases operational efficiency and lessens alert fatigue by minimizing the number of pointless notifications and freeing cybersecurity experts to concentrate on real threats.
AutoML Report
Because of its ability to provide comprehensive reports with informative data, MLJAR AutoML provides deep insights into model performance, data analysis, and evaluation measures. Below are a few instances of this kind.
Leaderboard
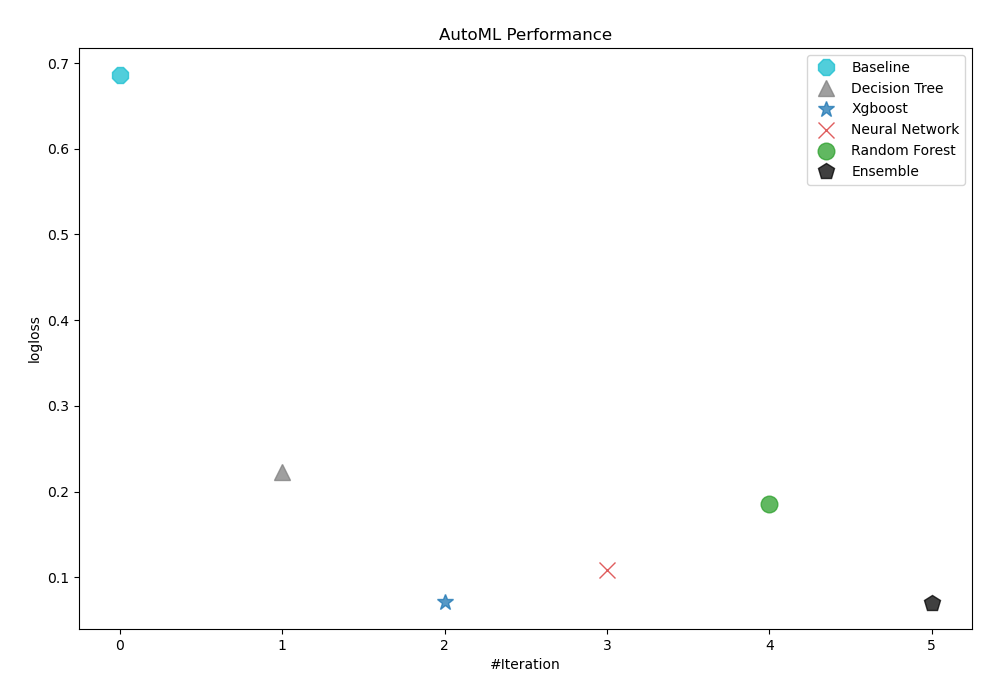
AutoML uses logloss as a performance metric to assess how well-trained models perform. Ensemble was finally chosen as the best model, as seen in the table and graph below.
| Best model | name | model_type | metric_type | metric_value | train_time |
|---|---|---|---|---|---|
| 1_Baseline | Baseline | logloss | 0.686607 | 1.34 | |
| 2_DecisionTree | Decision Tree | logloss | 0.222409 | 12.44 | |
| 3_Default_Xgboost | Xgboost | logloss | 0.0709204 | 8.22 | |
| 4_Default_NeuralNetwork | Neural Network | logloss | 0.108341 | 4.07 | |
| 5_Default_RandomForest | Random Forest | logloss | 0.185618 | 6.46 | |
| the best | Ensemble | Ensemble | logloss | 0.0704827 | 1.61 |
AutoML Performance
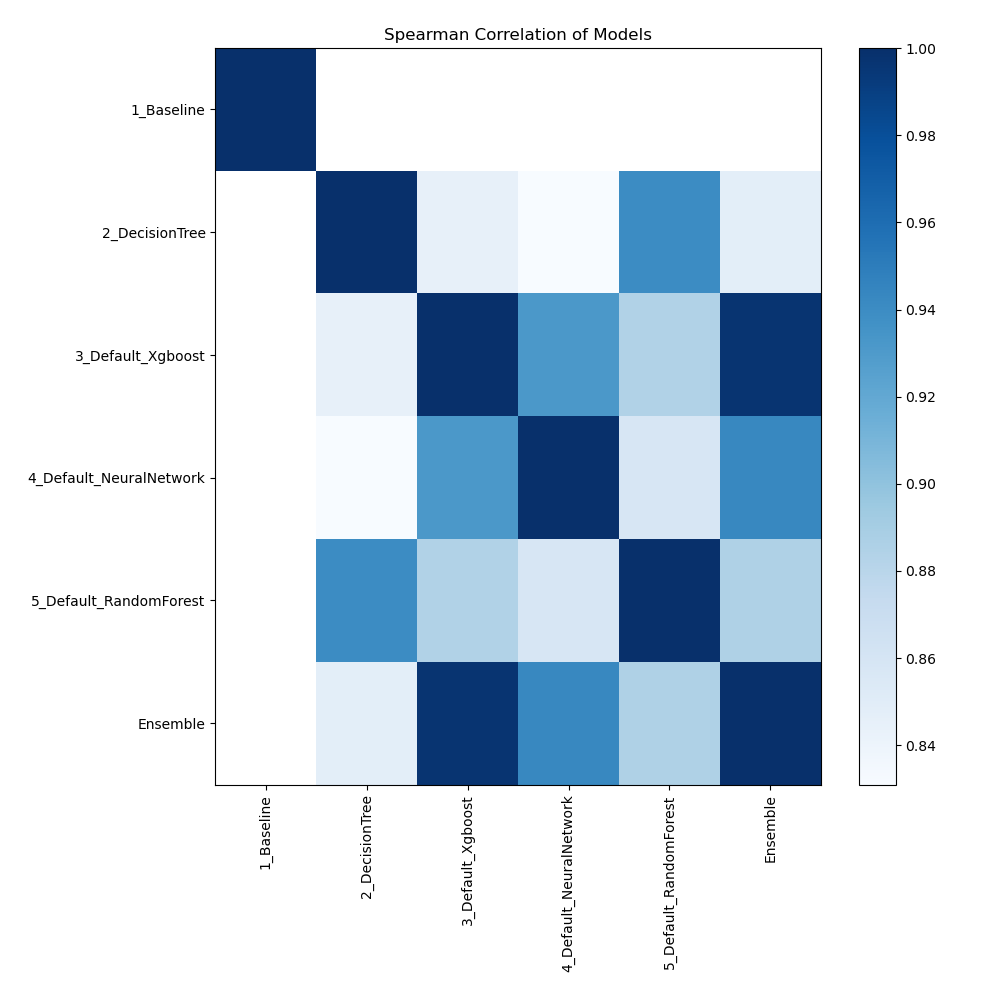
Spearman Correlation of Models
The plot illustrates the relationships between different models based on their rank-order correlation. Spearman correlation measures how well the relationship between two variables can be described using a monotonic function, highlighting the strength of the models' performance rankings. Higher correlation values indicate stronger relationships, where models perform similarly across different metrics or datasets.
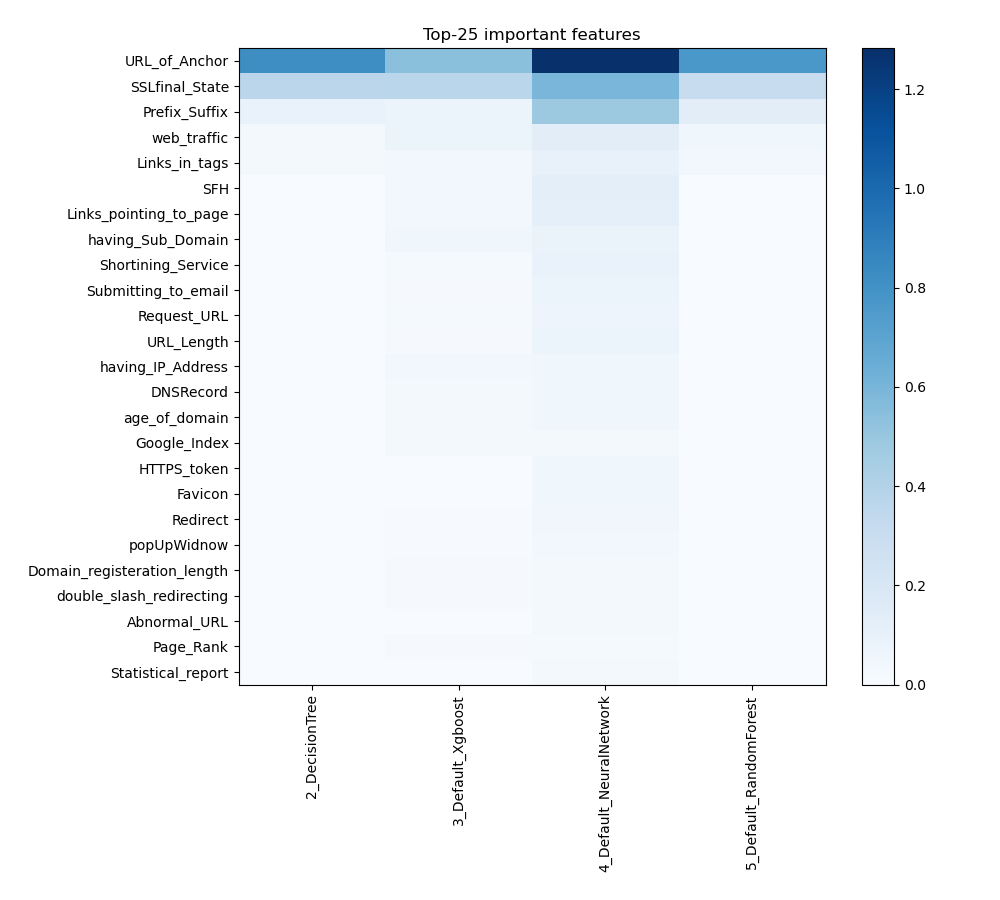
Feature Importance
The plot visualizes the significance of various features across different models. In this heatmap, each cell represents the importance of a specific feature for a particular model, with the color intensity indicating the level of importance. Darker or more intense colors signify higher importance, while lighter colors indicate lower importance. This visualization helps in comparing the contribution of features across multiple models, highlighting which features consistently play a critical role and which are less influential in predictive performance.
Install and import necessary packages
Install the packages with the command:
pip install pandas, mljar-supervised, scikit-learn
Import the packages into your code:
# import packages
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from supervised import AutoML
from sklearn.metrics import accuracy_score
Load dataset
Import the dataset containing information about phishing websites.
# read data from openml page
data = fetch_openml(data_id=4534, as_frame=True)
X = data.data
y = data.target
# display data shape
print(f"Loaded X shape {X.shape}")
print(f"Loaded y shape {y.shape}")
# display first rows
X.head()
Loaded X shape (11055, 30)
Loaded y shape (11055,)
| having_IP_Address | URL_Length | Shortining_Service | having_At_Symbol | double_slash_redirecting | Prefix_Suffix | having_Sub_Domain | SSLfinal_State | Domain_registeration_length | Favicon | ... | RightClick | popUpWidnow | Iframe | age_of_domain | DNSRecord | web_traffic | Page_Rank | Google_Index | Links_pointing_to_page | Statistical_report | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1 | 1 | 1 | 1 | -1 | -1 | -1 | -1 | -1 | 1 | ... | 1 | 1 | 1 | -1 | -1 | -1 | -1 | 1 | 1 | -1 |
| 1 | 1 | 1 | 1 | 1 | 1 | -1 | 0 | 1 | -1 | 1 | ... | 1 | 1 | 1 | -1 | -1 | 0 | -1 | 1 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 | 1 | -1 | -1 | -1 | -1 | 1 | ... | 1 | 1 | 1 | 1 | -1 | 1 | -1 | 1 | 0 | -1 |
| 3 | 1 | 0 | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | ... | 1 | 1 | 1 | -1 | -1 | 1 | -1 | 1 | -1 | 1 |
| 4 | 1 | 0 | -1 | 1 | 1 | -1 | 1 | 1 | -1 | 1 | ... | 1 | -1 | 1 | -1 | -1 | 0 | -1 | 1 | 1 | 1 |
5 rows × 30 columns
Split dataframe to train/test
To split a dataframe into train and test sets, we divide the data to create separate datasets for training and evaluating a model. This ensures we can assess the model's performance on unseen data.
This step is essential when you have only one base dataset.
# split data
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.95, shuffle=True, stratify=y, random_state=42)
# display data shapes
print(f"X_train shape {X_train.shape}")
print(f"X_test shape {X_test.shape}")
print(f"y_train shape {y_train.shape}")
print(f"y_test shape {y_test.shape}")
X_train shape (10502, 30)
X_test shape (553, 30)
y_train shape (10502,)
y_test shape (553,)
Fit AutoML
We need to train a model for our dataset. The fit() method will handle the model training and optimization automatically.
# create automl object
automl = AutoML(total_time_limit=300, mode="Explain")
# train automl
automl.fit(X_train, y_train)
Compute predictions
Use the trained AutoML model to make predictions on test data of phising websites.
# predict with AutoML
predictions = automl.predict(X_test)
# predicted values
print(predictions)
['1' '-1' '1' '-1' '-1' '1' '1' '1' '-1' '-1' '-1' '-1' '-1' '1' '-1' '1' '1' '1' '1' '1' '-1' '-1' '-1' '1' '1' '-1' '-1' '-1' '-1' '-1' '1' '-1'... '1' '-1' '-1']
Compute accuracy
We are comparing valid values with our predictions. To do that we will use accuracy score.
# compute metric
metric_accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {metric_accuracy}")
Accuracy: 0.969258589511754
Conlusions
In the realm of cybersecurity, MLJAR AutoML offers significant advantages by automating the analysis of complex security datasets and detecting potential threats. Organizations can improve the precision of threat detection and response plans by utilizing AutoML's capabilities, which enable them to spot trends and abnormalities faster than they could with conventional techniques. This automation increases the accuracy of predictive models for finding vulnerabilities and cyberattack vectors while also expediting the processing of massive volumes of security data. The incorporation of MLJAR AutoML can significantly enhance an organization's capacity to protect its digital assets in light of the ongoing evolution of cybersecurity threats, ultimately resulting in a more robust and proactive defense posture.
See you soon👋.