What are decision trees?
Decision tree is non-parametric, hierarchical, supervised model in a tree-like shape. It supports decision making algorithms based on different variables (e.g. costs, needs, event outcomes) and its possible consequences.
It consists of:
- root node
- internal nodes
- leaf nodes
- branches
- subtrees
Decision trees are versatile tools used for regression and classification. In addition they are commonly used in decision analasis helping to develop best strategies. Overfitting (find out more in article) is possible in decision trees too. In this case pruning can be used - like in a gardening, it is trimming unnecessarry branches.
Decision tree structure
You can also think about decision tree diagram as a flowchart helping to visualize plans or predictions.
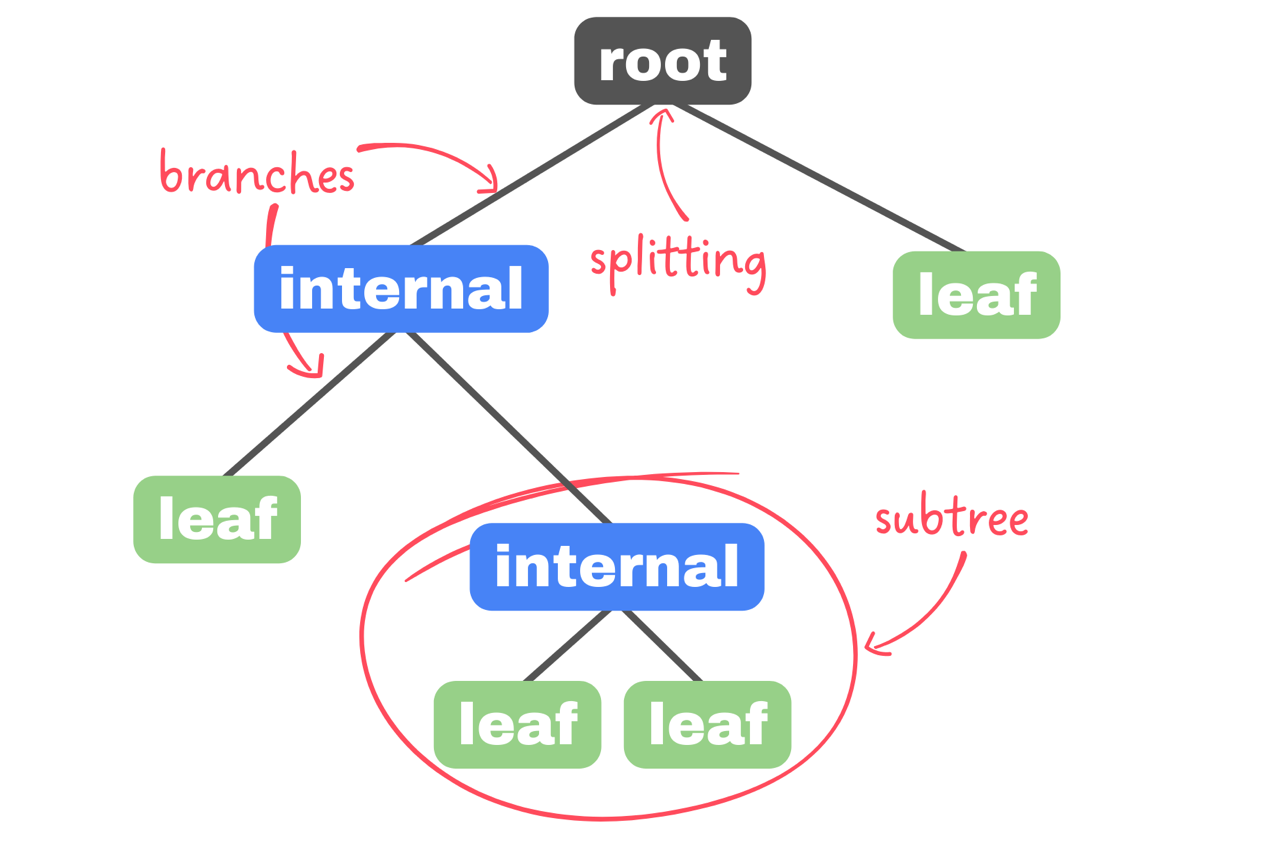
Our starting point is root node, single one node with only outgoing branches. It’s connected to internal/decision nodes. Each of those nodes must make a decision from given dataset. From every node comes out two branches, representing possible choices. The ending points of decision tree are leaf nodes – resolutions of integral nodes making decisions. Every leaf node has only one incoming branch and they represent all possible outcomes for our data. Possible is for decision tree to contain simillar leafs in different subtrees.
Best node-splitting functions and their use
Decision tree algorithms use many different methods to split nodes. It is a fundamental concept in those algorithms trying to achieve pure nodes (these nodes contain only one homogenous class – ergo, takes into consideration part of data that no other node does). Most popular, evaluating the quality of each test condition splitting methods are:
-
Entropy
- It’s a measure of impurity in dataset that ranges from 0 to 1 with too complex formula. The more elements evenly distributed among classes, the higher entropy. The more entropy, the more uncertain data. Do we want to have uncertain nodes? Not really. Machine learning goal in wider understanding is to make uncertain things clearer for us so we can split this uncertain node, however we don’t know how splitting a node influences certainty of parent node.
-
Gini impurity
- Other metric used in decision trees (sometimes named Gini index) and alternative to regression. It grades - 0 is fully organized, 0.5 is totally mixed - nodes to splitting based on organization of dataset so lower values are preferable.
-
Information gain
- It represents weight of the split, difference in entropy or Gini index before and after split. Information gain has tangled algorithm using both metrics. To properly train decision tree information gain is used to find its highest values and split it making continues subtrees. Creating algorithm in training focuses on prefferably single variables in dataset having most influance on result and positioning those splits higher in hierarchy of the tree.
Gini impurity is easier to compute than Entropy (summing and sqering instead of logarythms and multiplacations), so for time efficiency Gini inex is usually chosen over entrophy for decision tree algorithm.
Prons and cons
Decision trees have wide usage but are usually outperformed by more precise algorithms. However they shine most notably in data science and data-mining.
-
Advantages:
- easy to understand how they work - decision tree diagrams are not difficult to read, unlike some other models
- accessible - can be tuned to many different datasets with multiple tasks to perform
- quick training - flexible characteristics of decision trees make them require little to no training
-
Disadvantages:
- butterfly effect - small changes in dataset can "mutate" decission tree to very different structure
- costly - cause of requeiring more computing power is greedy algorythm at the base of this model
- need of proning - decision trees easily overfit in the face of new data
Conclusions
Decision trees are powerful and versatile machine learning algorithms that are widely used for bothclassification and regression tasks. Overall, decision trees are popular due to their simplicity, interpretability, and ability to handle various types of data and tasks. However, they require careful tuning to avoid overfitting and may not always perform as well as more complex algorithms on certain datasets. Nonetheless, they remain a valuable tool in the machine learning toolkit.